
 3
3 0
0这篇论文《面向知识密集型任务的检索增强生成技术综述》系统性地回顾了检索增强生成(RAG)技术的发展脉络、核心原理、关键技术、应用场景及未来挑战。以下是论文内容的总结:
一、核心主题与背景
论文旨在解决预训练语言模型在知识密集型任务中存在的知识封闭性、事实幻觉、时效性不足等问题。RAG通过融合信息检索与文本生成,引入外部知识源,显著提升了模型的知识覆盖率、事实准确性与时效性。
二、主要内容结构
- 基本原理与系统架构
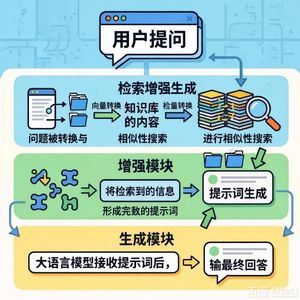
RAG范式:采用“开放式”生成,在生成前从外部知识库检索相关文档,作为生成条件,实现动态知识调用。
系统流程:分为编码、检索、融合、生成四个阶段,核心模块为检索器和生成器。
对比分析:与闭卷问答(依赖参数记忆)和检索式问答(直接返回文档片段)相比,RAG兼顾了语言自然性与事实一致性。 - 关键组件与技术
检索器:包括稠密检索(如DPR)、稀疏检索(如BM25)和混合检索,负责从知识库中筛选相关文档。
生成器:从可训练的Encoder-Decoder模型(如T5)演进到大型闭源模型(如GPT-4),解码策略与生成控制(如Prompt Engineering、PEFT)是优化重点。
协同机制:包括管线式训练、端到端联合训练、多轮交互式推理(如IRCoT),以及优化方法(如FiD、REALM、REPLUG)。 - 典型变体与扩展
FiD:采用“延迟融合”策略,独立编码文档,在解码阶段融合,提升多文档处理能力。
REALM:在预训练阶段引入检索机制,实现检索器与语言模型的深度耦合。
REPLUG:针对闭源大模型,冻结生成器、仅训练检索器,实现轻量化适配。
GraphRAG:引入知识图谱结构,增强语义组织与推理连贯性。
工具增强型RAG:结合外部工具调用(如ReAct),扩展模型执行与交互能力。
检索增强指令微调:在微调阶段引入检索,提升模型在少样本或领域迁移场景下的表现。 - 应用场景
开放域问答、智能客服、垂直领域问答(医疗、法律、金融)、企业知识管理、教育答疑、指令数据生成等。 - 评估方法检索质量指标(如Recall@k、MRR)、生成质量指标(如BLEU、BERTScore)、联合评估指标(如Faithfulness、Hallucination Rate)。
- 挑战与未来方向
挑战:检索误差传播、冗余冲突文档融合、事实一致性验证、知识库动态更新、训练成本高、评估标准不统一。
未来方向:主动/自适应检索、检索-生成联合优化、多模态RAG、小样本/无监督训练、与知识图谱/外部工具深度融合、可解释性评估。
三、论文贡献
- 系统梳理了RAG的技术演进路径,从早期架构到当前前沿变体。
- 提供了统一的理论框架,明确了RAG在知识密集型任务中的优势与局限。
- 为后续研究指明了关键挑战与发展方向,兼具理论价值与实践参考意义。
四、结论
RAG作为连接外部知识与语言生成的重要范式,已成为构建高可信、可验证AI系统的核心技术。未来,随着多模态融合、工具交互与评估体系的完善,RAG将在更多领域发挥关键作用。
每一章的核心内容与主要信息分析如下:
第一章:引言
本章阐明了论文的写作背景与核心议题。指出预训练语言模型(PLMs)虽在自然语言处理中取得进展,但其知识封闭性、事实幻觉和时效性不足等问题限制了在知识密集型任务中的应用[^论文]。为解决这些问题,检索增强生成(RAG)技术应运而生,它通过融合信息检索与文本生成,使模型能动态调用外部知识,从而提升生成内容的准确性、时效性和可解释性[^论文]。本章最后概要性地介绍了全文的六个主要内容,为后续章节的展开奠定了基础。
第二章:基本原理与系统架构
本章系统阐述了RAG的技术范式与整体框架。首先,明确了RAG是一种 “开放式”生成范式,其核心是在生成前从外部知识库中检索相关文档作为条件输入,以此弥补纯参数化模型的不足[^论文]。其次,详细拆解了RAG的四阶段系统流程:编码、检索、融合与生成[^论文]。最后,通过对比闭卷问答(依赖内部知识,易产生幻觉)、检索式问答(直接返回文档片段,缺乏生成灵活性)和RAG问答(兼顾检索的事实性与生成的自然性)三种范式,凸显了RAG在知识密集型任务中的平衡优势[^论文]。这与外部资料中描述的RAG“检索-增强-生成”工作流程和其解决“幻觉荒野”问题的价值高度吻合。
第三章:RAG关键组件与技术
本章深入剖析了构成RAG系统的两大核心模块及其协同机制。
- 检索器:负责从知识库中筛选相关信息。主流方法包括稠密检索(如DPR,基于向量语义匹配)、稀疏检索(如BM25,基于关键词匹配)以及结合二者优点的混合检索[^论文]。
- 生成器:负责基于查询和检索到的文档生成最终答案。其演进路径是从可训练的开源Encoder-Decoder模型(如T5)转向高性能的闭源大语言模型(如GPT-4)。生成质量的控制依赖于解码策略(如束搜索、Top-p采样)和提示工程、参数高效微调等技术[^论文]。
- 协同机制:检索器与生成器的协作方式至关重要,主要包括管线式训练、端到端联合训练(如REALM)以及模拟逐步推理的多轮交互式检索生成(如IRCoT)[^论文]。此外,FiD(延迟融合)、REPLUG(适配黑盒模型)等优化方法被提出,以提升两模块的协同效率与系统性能[^论文]。
第四章:RAG的变体
本章总结了在基础RAG架构上的重要演进与扩展方向,展示了该技术的多样性与适应性。
- 架构优化:如FiD通过独立编码文档、在解码器融合的策略,提升了多文档处理能力;REALM在预训练阶段引入检索,实现了深度耦合;REPLUG则专注于训练检索器以适配不可训练的闭源大模型[^论文]。
- 能力扩展:GraphRAG引入知识图谱结构,增强语义组织与推理能力;工具增强型RAG(如结合ReAct框架)使模型能调用外部API,执行复杂任务;检索增强指令微调将检索机制融入模型微调过程,提升其在少样本和领域迁移任务上的表现[^论文]。这些变体共同推动了RAG从简单的文本融合向知识融合与智能体行为方向发展。
第五章:应用场景
本章列举了RAG技术在多个领域的成功实践,证明了其广泛的实用价值。主要应用包括:开放域问答系统、智能客服与对话系统、医疗/法律/金融等垂直领域问答、企业知识管理与智能助手、教育场景中的自动答疑,以及指令数据生成与增强[^论文]。这些应用的核心优势在于,RAG能够利用专属、动态更新的知识库,使大模型输出更具专业性、精准性和可追溯性,从而有效服务于具体行业需求。在软件工程领域,RAG也被应用于代码生成、程序修复等任务,相关研究自2021年起呈现显著增长趋势。
第六章:评估方法
本章指出,由于RAG系统包含检索与生成两个环节,其评估体系也需兼顾两者。论文将现有评估指标分为三类:
- 检索质量指标:如Recall@k、MRR,衡量检索结果的相关性。
- 生成质量指标:如BLEU、BERTScore,衡量生成文本的质量。
- 联合评估指标:如Faithfulness(忠实性)、Answer Groundedness(答案溯源性)、Hallucination Rate(幻觉率),这些指标对于衡量RAG系统生成内容的事实一致性与可靠性尤为关键[^论文]。目前,该领域尚缺乏统一、全面的评估基准。
第七章:挑战和研究方向
本章客观分析了当前RAG技术面临的主要挑战,并展望了未来可能的发展路径。
- 核心挑战包括:检索误差传播、冗余冲突文档融合困难、事实一致性验证不足、知识库动态更新难题、训练成本高昂以及评估体系不统一[^论文]。
- 未来方向则聚焦于:开发更智能的主动与自适应检索机制、探索更深度的检索-生成联合优化、发展多模态RAG、研究小样本/无监督训练方法、实现与知识图谱及外部工具的深度融合,以及建立更完善的可解释性评估体系[^论文]。
第八章:结束语
本章对全文进行了总结,重申了RAG技术在解决大模型知识局限性、提升生成内容可信度方面的核心价值。论文回顾了RAG从早期可训练架构到当前解耦式“检索器+黑盒大模型”范式的演进脉络,并强调了其在构建高可信、可验证的AI系统,以及推动AI原生应用发展中的关键作用[^论文]。
