
- PageIndex:RAG for Technical Manuals-Challenges and Solutions
根据提供的文章,本文主要探讨了检索增强生成(RAG)在技术手册应用中的挑战与解决方案。核心内容总结如下: 1. 背景与问题: * 工业技术手册(如制冷机、PLC系统手册)通常长达数百页、更新频繁且结构复杂,手动查找信息效率低下。 * 尽管大语言模型(LLM)支持长上下文,但性能会随文本长度增加而下降。因此,RAG成为主流解决方案,它通过检索最相关的文本片段来优化上下文。 * 然而,传统的基于向量的RAG方法在应对技术手册时存在根本性局限。 2. 传统向量RAG的四大局限(通过实例说明): * 缺乏推理能力:仅依赖静态语义相似性匹配,无法理解步骤顺序或多跳因果关系(例如,检索到更换干燥机的步骤,却漏掉了相关的制冷剂安全警告)。 * 分块破坏语义完整性:将文档硬性分割成固定大小的文本块(分块),常会切断句子、段落或章节,导致相关上下文碎片化(例如,一个完整的检查清单被分割到两个块中,导致模型只能看到一部分)。 * 低召回率导致信息缺失:技术手册中许多术语语义相似但所指不同,向量检索可能因固定返回数量(top-K)和单次检索而错过真正相关的段落(例如,查询“高温环境导致机组进入机械模式的原因”,却检索到了关于“高温故障”的无关内容)。 * 低精确度导致上下文混淆:由于许多不同程序共享相似术语,向量检索会返回大量冗余或无关的文本块,导致模型接收到混合甚至矛盾的信息,产生错误答案或“幻觉”(例如,混淆了“开环”和“闭环”系统中乙二醇泵的作用)。 3. 提出的解决方案:PageIndex(基于推理的、无向量检索框架) * 该框架模仿人类查阅手册的自然过程,采用动态、迭代的推理进行检索,而非依赖静态语义相似性。 * 核心流程为:阅读目录 → 选择可能相关的章节 → 提取信息 → 判断信息是否充足 → 若不足则重复此循环。 * 如何克服上述局限:具备推理能力:能根据已检索内容推断逻辑缺口(如 prerequisite、警告),并主动跳转到相关章节填补。 保持结构完整:不依赖硬分块,而是按文档的自然逻辑边界(如完整章节)进行检索,确保信息单元完整。 实现高召回率:通过迭代推理,持续评估信息是否足以回答问题,确保收集所有必要细节。 实现高精确度:基于逻辑定位到具体相关章节,避免检索语义相似但无关的“看起来像”的内容,确保上下文聚焦。 4. 总结对比: 文章通过一个对比表格和多个基于真实技术手册的问答实例,清晰地展示了向量RAG与基于推理的RAG(PageIndex) 在应对技术手册时的性能差异。结论指出,PageIndex这类方法使LLM能够像现场工程师一样逻辑性地导航技术手册,标志着从简单搜索引擎向真正智能文档理解的转变。 根据提供的文章《RAG for Technical Manuals》,其章节内容详细介绍如下: 1. 引言 * 核心问题:工业技术手册(如安装、维护指南)通常篇幅长、更新频繁且复杂。人工查阅效率低下,导致维修时间长、错误率高和设备停机成本增加。 * 现有方案与局限:虽然大语言模型支持长上下文,但研究表明随着上下文增长,模型性能会下降。检索增强生成(RAG)成为主流解决方案,它通过检索与查询最相关的文本片段来优化有效上下文长度。然而,传统的基于向量的RAG方法依赖静态语义相似性,存在关键局限。 2. 基于向量的RAG的局限性 本章详细阐述了传统向量RAG在应用于长而复杂的技术手册时面临的四个根本性挑战: * 缺乏推理能力:仅基于静态语义相似性匹配检索文本,无法理解步骤顺序或多跳因果关系。 * 分块破坏语义完整性:将文档硬性分割为固定大小的块(如512或1000个标记),通常会切断句子、段落或章节,导致上下文碎片化。 * 低召回率导致信息缺失:技术手册中许多段落语义相似但相关性不同,在固定top-K检索和单次检索下,真正相关的部分常常无法被检索到。 * 低精确度导致上下文混淆:由于检索到许多语义相似的段落,大语言模型会收到冗余甚至不一致的文本块,导致答案嘈杂且有时不正确。 3. PageIndex:基于无向量推理的检索 本章介绍了PageIndex框架,这是一种模仿人类自然浏览长文档方式的推理检索方法。 * 核心原理:不同于依赖静态语义相似性的传统方法,它采用动态、迭代的推理过程,基于问题的演进上下文主动决定下一步查找位置。 * 工作流程:阅读目录,理解文档结构并识别可能相关的章节。 根据问题选择最可能包含有用信息的章节。 解析所选章节以收集有助于回答问题的内容。 判断信息是否充分。如果否,则返回步骤1,循环选择另一章节;如果是,则回答问题。 4. 克服技术手册中基于向量的RAG局限性 本章通过并排的问答示例,具体分析了上述四个局限性,并展示PageIndex的推理框架如何克服它们。对比双方是:基于向量的RAG(以Google的Gemini File Search RAG API为例)和基于推理的RAG(以PageIndex Chat为例)。 * 针对“缺乏推理能力”:向量RAG失败案例:对于“如何更换干燥器及适用哪些安全预防措施?”的问题,它只检索到第29页的机械步骤,但遗漏了第6页关键的“制冷剂警告”。 PageIndex成功案例:通过结构感知推理,在找到干燥器程序后,根据步骤中提到的“制冷剂泄漏”推断需要安全指导,进而检索到第6页的警告。 * 针对“分块破坏语义完整性”:向量RAG失败案例:对于关于“安装前检查清单”和“吊耳位置图示”的问题,由于固定分块,检索的文本块在清单开始处截断,导致模型看不到后续的实际列表项;同时因语义权重偏差,遗漏了部分图示(图5-7)。 PageIndex成功案例:通过无分块策略和结构感知,在文档结构层面操作,保持了清单内容和相关说明的完整性;并通过推理引用关系,捕获了全部相关图示(图5-12)。 * 针对“低召回率导致信息缺失”:向量RAG失败案例:对于“为何高环境温度会导致机组进入机械模式?”的问题,它检索到描述“高环境温度故障”的文本,但未检索到第142页解释控制逻辑机制的关键部分。 PageIndex成功案例:通过迭代推理和结构感知,首先定位到“运行模式”章节,然后综合多步控制逻辑,正确解释了触发机制,并检查了相关页面以验证上下文。 * 针对“低精确度导致上下文混淆”:向量RAG失败案例:对于“闭式自由冷却何时需要乙二醇泵?”的问题,它同时检索到开环和闭环系统的段落,由于术语相似,模型混淆了细节,给出了包含阀门(属于开环)和虚构的泵充电功能等错误答案。 PageIndex成功案例:通过逻辑导航,直接定位到描述闭环配置的特定章节,排除了混淆的开环内容,给出了准确答案。 5. 总结:向量检索与推理检索的RAG对比 本章通过一个对比表格总结了两种方法的差异: * 缺乏推理:向量RAG仅执行静态相似性搜索;推理RAG将检索视为动态推理过程。 * 分块破坏完整性:向量RAG的硬分块导致上下文割裂;推理RAG避免人工分块,保留完整文档结构。 * 低召回率:向量RAG常因术语差异遗漏相关信息;推理RAG通过迭代推理确保高召回率。 * 低精确度:向量RAG检索冗余相似块导致上下文混淆和幻觉;推理RAG基于逻辑导航到特定相关章节,避免噪声。 6. 结论 * 文章总结,对于技术手册等复杂长文档,基于向量的RAG存在结构上的根本限制。PageIndex提出的基于推理的检索框架通过模仿人类专家的逻辑导航和迭代查找,有效克服了这些限制。 * 它使大语言模型能够像现场工程师一样逻辑清晰地浏览技术手册,标志着从简单搜索引擎向真正智能文档理解系统的转变,可提供可靠、上下文感知且符合实际工作流程的答案。
13分钟 · 37
37 0
0 - PageIndex Leads Financial QA Benchmark
根据提供的文章,这是一篇关于PageIndex框架在金融问答(QA)基准测试中取得领先性能的介绍。主要内容总结如下: 1. 核心问题:传统基于向量检索的RAG系统在处理复杂、结构化的金融文档(如SEC财报)时,因细微的语义差异容易导致答案错误。 2. 解决方案:提出了 PageIndex 框架。其核心创新在于放弃传统的语义相似性搜索,改为模仿人类专家的推理方式:将文档转换为层次化的树状结构,完整保留原文的章节、表格等内在逻辑。 基于此结构进行推理驱动的检索,引导模型像分析师一样“思考”答案可能位于文档的哪个部分。 3. 应用与性能:基于PageIndex构建了专门用于金融文档分析的RAG模型 Mafin 2.5。在行业标准基准 FinanceBench(要求从SEC文件中直接寻找答案)上进行了测试。 取得了98.7%的准确率,显著超越了其他主流模型(如Fintool、Finchat、Perplexity及GPT-4o结合搜索等),达到了领先水平。 4. 成功原因:文章最后解释了PageIndex表现优异的三个关键点:保持文档结构:完整保留金融报告固有的层次。 可追溯的检索:每个检索步骤都有元数据记录,过程可解释。 推理驱动搜索:不依赖语义匹配,而是通过逻辑推理定位答案。 总结:本文介绍了一种名为PageIndex的新型检索框架,它通过模仿人类推理和利用文档层次结构,显著提升了从复杂金融文档中回答问题的准确性,其代表模型Mafin 2.5在权威基准测试中取得了最佳成绩。 根据提供的文章,以下是每个章节的详细介绍: 1. 引言 (Introduction) 本章节介绍了PageIndex框架及其在金融问答领域的实际应用。PageIndex是一个基于推理的检索框架,其核心思想是模仿人类专家阅读、导航和从复杂文档中提取信息的方式。与传统的基于向量语义相似性搜索的方法不同,PageIndex将文档转换为分层树状结构。这种方法在金融等领域尤其有效,因为微小的语义差异就可能导致答案错误。 2. PageIndex在金融问答中的应用 (PageIndex in Financial Question Answering) 本章节具体说明了基于PageIndex构建的金融应用Mafin 2.5。Mafin 2.5是一个专为金融文档分析设计的、最先进的基于推理的RAG模型。它在行业标准基准测试FinanceBench上取得了98.7%的市场领先准确率,显著超越了传统的基于向量的RAG系统。PageIndex的分层索引能力使其能够从复杂的财务报告(如SEC备案文件和收益披露)中进行精确导航和内容提取。详细的基准测试结果可在其GitHub仓库中查看。 3. 性能基准 (Performance Benchmark) 本章节解释了用于评估的基准测试FinanceBench。它是一个行业标准基准,旨在评估大语言模型在金融问答任务上的性能。该基准包含关于上市公司的各种问题,要求模型必须直接从SEC文件(如10-K、10-Q、8-K)中寻找答案。文章列举了来自FinanceBench的两个示例问题,例如关于AMD公司流动性的问题,以及关于摩根大通业务部门营收的问题。 4. 最先进的准确率 (State-of-the-Art Accuracy) 本章节通过一个对比表格,展示了Mafin 2.5与其他主流模型在FinanceBench上的准确率表现。关键数据如下: * Mafin 2.5:以98.7% 的准确率位居榜首。 * 其他对比模型包括:Fintool (98%)、Finchat (91%)、Perplexity (45%)、GPT-4o结合搜索 (31%)、上一代的Mafin2 (94%) 以及Quantly (94%)。 这突出了Mafin 2.5(基于PageIndex)在该领域的领先优势。 5. PageIndex为何表现优异 (Why PageIndex Works Well) 本章节深入分析了PageIndex能在金融QA用例中取得顶尖准确率的三个关键原因: 1. 保留文档结构:财务报告本身具有层次化结构(章节、表格、脚注、附录)。PageIndex直接保留了这种层次,而不是将其打碎成人工划分的文本块。 2. 可追溯的检索:PageIndex树中的每个节点都可以携带元数据(如页码范围、章节标题),这使得每一步检索都是可追溯和可解释的。 3. 推理驱动的搜索:PageIndex不依赖于语义相似性,而是引导模型推理答案应该位于文档的哪个部分——这类似于分析师如何导航一份10-K报告。
9分钟 ·230 - PageIndex:用树状推理索引重新定义RAG检索性能
根据提供的文章,以下是关于PageIndex论文的主要内容总结: 核心主题:PageIndex是一种创新的检索增强生成(RAG)系统,它通过无向量推理架构和树状索引结构,从根本上重新定义了RAG的检索范式,旨在解决传统向量检索方案的关键痛点。 背景与痛点:传统RAG系统依赖向量相似度搜索,存在语义鸿沟(相似性不等于相关性)、上下文碎片化(固定分块破坏文档结构)以及检索精度与召回率难以兼顾等问题。 核心技术创新: 1. 无向量依赖设计:摒弃嵌入模型和向量数据库,降低技术复杂性和维护成本。 2. 结构化树状索引:将文档智能分析并组织成层次化的树形结构(类似目录),保留文档的天然逻辑和语义关联。 3. 推理式检索机制:利用大语言模型(LLM)的推理能力,模拟人类专家“思考”和“导航”文档的过程,从树状索引中定位最相关的内容,而非进行简单的相似度匹配。 工作原理: 1. 文档树状索引生成:分析文档整体结构与语义,自动生成具有层次节点(包含摘要、标签、位置信息)的树状索引。 2. 推理式树搜索检索:面对查询时,系统执行多步推理:理解查询意图、在树状索引中选择导航路径、深度遍历提取内容、并进行相关性验证。 性能突破:在专业的FinanceBench金融问答基准测试中,PageIndex取得了98.7%的准确率,显著超越了传统向量检索方案,证明了其推理式检索在处理复杂、结构化文档方面的优越性。 核心优势: * 检索透明化:检索过程可解释,能展示推理路径。 * 类人化操作:模拟专家思维,理解深层语义关联。 * 零依赖维护:无向量模型升级或数据库扩展的瓶颈。 * 高精度召回与结构化理解:能准确提取所需信息并保持文档元素间的逻辑关联。 技术实现与部署:涉及智能的语义层次分析索引构建、多路径探索与推理相关性评分算法,并提供云服务、API及支持本地部署的开源版本。 未来展望:技术方向包括多模态扩展、跨文档推理等;在金融、法律、科研教育等行业有广阔应用前景。 总结意义:PageIndex标志着RAG技术从“相似度匹配”向“推理式检索”的重要转变,是推动AI向“认知智能”发展的一个重要里程碑。 根据提供的文章,以下是每个章节的详细内容介绍: 引言:RAG 检索优化的行业痛点 本章节阐述了传统检索增强生成(RAG)系统在2025年面临的核心挑战。主要痛点包括: 1. 语义鸿沟问题:基于向量相似度的检索经常找到“看似相似”而非真正相关的内容,在处理金融、法律等专业文档时尤为突出。 2. 上下文碎片化困境:为适应模型上下文窗口而进行的固定文档分块,破坏了文档原有的结构和语义关联。 3. 检索精度与召回率的两难:传统方案难以在检索速度和准确性之间取得平衡。 这些痛点引出了对一种能像人类专家一样进行导航式检索的新范式的需求。 PageIndex: 重新定义 RAG 检索范式 本章介绍了PageIndex的总体定位。它是由VectifyAI开发的创新型RAG系统,其核心理念是采用 “无向量、基于推理” 的架构,并通过构建树状索引结构来模拟人类专家的文档导航方式,旨在实现检索性能的突破。 核心技术创新 本章详细说明了PageIndex与传统向量RAG的根本区别,其创新体现在三个方面: 1. 无向量依赖设计:摒弃嵌入模型和向量数据库,避免语义损失,降低技术复杂性和维护成本。 2. 结构化树状索引:将文档组织成保留天然层次关系的树形结构(类似目录),为推理提供数据基础。 3. 推理式检索机制:利用大语言模型(LLM)的推理能力,让系统像人类一样“思考”和“导航”树状索引,从根本上解决相似性搜索的局限。 工作原理深度解析 本章分两步详解了PageIndex的工作流程: 1. 文档树状索引生成:系统智能分析文档的语义和结构逻辑,自动生成层次化的树状索引(例如,将年报分解为“财务状况”等章节及其子章节),每个节点包含摘要、页码和标签。 2. 推理式树搜索检索:面对查询时,系统模拟人类思维:理解查询意图。 在树状索引中选择最相关的导航路径。 沿路径深度遍历,提取相关片段。 利用LLM推理验证结果的相关性。 这种方式能精准捕捉文档的逻辑关系和语义联系。 性能突破:98.7%准确率的里程碑 本章聚焦于PageIndex在FinanceBench(一个金融问答基准测试)上取得的98.7% 的准确率成绩。这标志着RAG技术的重要里程碑,显著超越了传统向量检索方案,验证了推理式检索在处理专业、复杂文档上的优越性。本章还分析了其核心优势: * 检索透明化:过程可解释,展示推理路径。 * 类人化操作:具备类似专业分析师的判断能力。 * 零依赖维护:无向量设计降低了维护成本和复杂性。 实际应用效果 本章列举了PageIndex在实际部署中展现的优势: * 高精度召回:显著降低“答非所问”的风险。 * 结构化理解:能保持图表、公式等复杂元素的完整性和逻辑关联。 * 动态适应性:能根据不同文档类型和查询模式自动调整策略。 技术实现细节与工程考量 本章深入介绍了系统的工程实现: * 索引构建策略:进行语义层次分析,识别主题与结构。 为每个节点自动生成内容摘要和关键词标签。 管理精确的页码和字符位置信息。 * 推理检索算法:多路径探索:同时探索多条路径,通过推理选择最优。 相关性评分机制:基于推理,综合内容匹配度、逻辑关联性等多维度评分。 结果验证优化:多层次验证确保结果符合用户意图。 * 系统集成与部署:提供云服务(Agent、API、Dashboard)和开源本地部署选项。 支持PDF、Markdown等多种文档格式。 未来发展与应用展望 本章展望了PageIndex的技术演进和行业应用前景: * 技术演进方向:支持图像、表格等多模态索引检索。 发展跨文档推理能力。 提升实时索引更新能力。 * 行业应用前景:金融服务:风险管理、投资分析等。 法律服务:合同分析、法条检索等。 科研教育:学术文献分析、知识图谱构建等。 总结: RAG 技术的重要里程碑 本章对全文进行总结,指出PageIndex标志着RAG技术从 “相似度匹配”向“推理式检索” 的重要转变。它通过无向量架构和树状索引,成功解决了传统RAG的核心痛点。98.7%的准确率有力证明了这一范式的有效性,为AI应用从“感知智能”向“认知智能”发展指明了方向。
10分钟 ·120 - PageIndex: Next-Generation Vectorless, Reasoning-based RAG
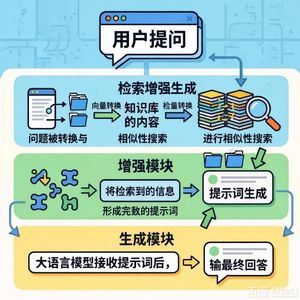
这篇论文介绍了 PageIndex,一种下一代、无向量、基于推理的检索增强生成(RAG)框架,旨在克服传统向量检索RAG的局限性。 核心问题:传统向量RAG的不足 论文首先指出,尽管RAG通过检索相关文本来缓解大语言模型(LLM)的上下文窗口限制,但主流的基于向量的RAG方法存在根本缺陷: 1. 查询与知识空间不匹配:查询表达意图,而向量检索只匹配语义相似的内容。 2. 语义相似性不等于相关性:在专业文档中,许多段落语义相近但相关性不同。 3. 硬分块破坏语义完整性:将文档固定分块会割裂上下文和逻辑。 4. 无法整合聊天历史:每次查询独立处理,缺乏多轮对话的连贯性。 5. 难以处理文档内部引用:无法有效跟踪如“参见附录G”这类跨章节引用。 解决方案:PageIndex的推理检索 PageIndex摒弃了向量数据库和静态语义相似性匹配,提出一种基于推理的动态检索方法,其核心是让LLM像人类一样“思考”并导航文档结构。关键流程如下: 1. 读取目录:理解以JSON层次化结构(“目录树”)表示的文档索引。 2. 选择章节:基于问题推理,选择最可能包含答案的章节。 3. 提取信息:根据node_id定位并读取该章节的原始内容。 4. 判断信息是否充足:若不足,则返回步骤1选择新章节;若充足,则生成答案。 核心创新与优势 * 无向量索引:使用结构化的“目录树”作为上下文内索引,LLM可直接对其进行推理和导航,而非依赖预计算的向量。 * 动态与连贯:检索完整的语义章节(而非固定分块),并根据需要迭代获取相邻部分,保持上下文连贯。 * 上下文感知:能够利用聊天历史来理解当前问题,实现连贯的多轮探索。 * 智能引用追踪:通过目录树结构,可以自然地跟随文档内的交叉引用找到相关信息。 总结 论文的结论是,向量RAG搜索相似文本,而推理RAG思考应该去哪里查找以及为什么。PageIndex通过结合结构化文档表示(目录树)和迭代推理,使LLM能够检索到真正相关的信息,而不仅仅是语义相似的信息,为新一代智能文档理解系统开辟了道路。 根据提供的文章,以下是关于PageIndex推理式RAG框架各章节内容的详细介绍: 1. 背景与问题引入 文章开篇指出,尽管大语言模型(LLM)能力强大,但其上下文窗口存在根本性限制,即使上下文增长,性能也会下降。为了应对此限制,检索增强生成(RAG)成为主流方案。然而,传统的基于向量的RAG方法依赖静态语义相似性,存在多个关键缺陷。为此,文章引入了PageIndex——一个基于推理的检索框架。 2. 基于向量的RAG的局限性 本章节详细阐述了传统向量RAG的五大核心问题: 1. 查询与知识空间不匹配:查询往往表达意图,而非具体内容,但向量检索假设语义最相似的文本就是最相关的。 2. 语义相似性不等于相关性:在专业文档(如财务、法律文件)中,许多段落语义相近但相关性截然不同。 3. 硬分块破坏语义和上下文完整性:将文档机械地切分为固定长度的文本块,会割裂完整的语义单元。 4. 无法整合聊天历史:每次查询都被独立处理,检索器不了解之前的对话上下文。 5. 难以处理文档内部引用:对于“参见附录G”这类引用,由于与引用内容缺乏语义相似性,传统RAG无法有效追踪。 3. PageIndex:基于推理的检索 本章节是文章的核心,介绍了PageIndex的工作原理。它模仿人类阅读长文档的方式,采用动态、迭代的推理过程: 1. 阅读目录(ToC):理解文档结构,识别可能相关的章节。 2. 选择一个章节:基于问题,选择最可能包含有用信息的章节。 3. 提取相关信息:从选定的章节中提取关键内容。 4. 信息是否充分?是 → 进入第5步回答问题。 否 → 返回第1步,选择另一个章节继续循环。 5. 回答问题:收集足够信息后,生成完整、有依据的答案。 文章通过一个流程图直观展示了这个迭代过程。 4. 为LLM设计的“目录”索引 本章节解释了如何为LLM构建友好的导航结构。PageIndex使用基于JSON的层次化结构来表示目录(ToC),形成一个索引树。每个节点代表一个逻辑部分(如章节、段落),包含node_id、description、metadata和sub_nodes等字段。这种“上下文内索引”使LLM能够直接引用、导航和推理,从而动态决定下一步查看哪里,而非依赖预先计算的相似度分数。 5. 如何克服传统RAG的局限性 本章节逐一对应地说明了PageIndex的推理式检索如何解决第二部分提出的五个问题: 1. 解决查询-知识不匹配:通过推理推断答案可能位于哪个章节(例如,“债务趋势通常在财务摘要部分或附录G”)。 2. 区分语义相似性与真正相关性:通过解读目录和查询意图,导航到实际包含答案的章节,即使其语言表述不同。 3. 避免硬分块导致的语义断裂:检索语义连贯的完整部分(如整页、整节),并在需要时迭代获取相邻部分以保持逻辑连续性。 4. 整合聊天历史:利用先前的对话历史来 refine 对当前问题的理解,实现跨多轮对话的连贯探索。 5. 有效处理文档内部引用:利用目录或PageIndex的层次结构,像人类一样跟踪文内引用(如“参见附录G”),实现准确的交叉引用。 6. 总结:向量RAG与推理式RAG的对比 文章通过一个对比表格,总结了两种方法的本质区别: * 向量RAG:搜索相似的文本。 * 推理式RAG:思考应该去哪里查找以及为什么。 关键区别体现在知识匹配、相关性判断、分块方式、上下文整合和跟踪引用这五个方面。推理式RAG通过结合结构化文档表示(如目录树)和迭代推理,使LLM能够检索到相关的信息,而不仅仅是相似的信息。 7. 结论与推广 文章最后得出结论,基于推理的RAG为新一代智能文档理解系统铺平了道路。同时提供了GitHub仓库链接以供查看开源代码,并说明PageIndex服务可作为ChatGPT风格的聊天平台使用,或通过MCP/API进行集成。
9分钟 ·80 - 面向外部时序相关语料抽取的无向量检索增强生成模型
这篇论文提出了一种非向量检索增强生成模型,旨在解决传统检索增强生成模型在处理多索引关联复杂查询时准确率不足的问题。 核心内容总结如下: 1. 研究背景与问题:传统RAG模型依赖向量数据库进行语义相似性匹配,但在处理具有强索引关联(如时间范围、多条件筛选)的复杂查询时,性能显著下降。 2. 提出方法:作者提出了NVRAG模型。其核心创新在于:引入非向量数据库:在构建知识库时,不仅生成向量数据,还将易于提取的结构化元数据存储在独立的非向量数据库中。 集成文本到SQL技术:当检测到用户查询包含明确的结构化条件时,利用文本到SQL模型将自然语言查询转换为精确的SQL语句。 两阶段检索:先使用SQL在非向量数据库中进行精确筛选,大幅缩小相关文档的范围;然后在此范围内,再进行传统的向量相似性匹配,最后将结果交给大语言模型生成答案。 3. 实验验证:在天气简报数据集上的实验表明,对于时间相关查询,NVRAG在忠实度和准确率上显著优于传统RAG模型,但其响应时间有所增加。 4. 结论:NVRAG通过结合非向量精确查询和向量语义匹配,有效提升了处理复杂关联查询的能力,但以牺牲一定的响应速度为代价。该方法对知识库文档的结构化程度有一定要求。 简言之,论文通过“先用SQL精确圈定范围,再用向量搜索细化内容”的策略,增强了RAG处理复杂问题的准确性。 根据提供的文章《A Non-Vector Retrieval-Augmented Generation Model for External Time-Relevant Corpus Extraction》,以下是各章节内容的详细介绍: 1. 摘要 本章节概括了全文的核心内容。它指出,尽管大语言模型(LLM)和检索增强生成(RAG)技术在处理未训练的外部语料库方面表现出色,但在处理具有强索引关联性(如时间相关)的复杂查询时,准确性较低。为此,本文提出了一种非向量检索增强生成(NVRAG)模型。该模型基于非向量数据库和文本转SQL(Text-to-SQL) 技术,通过存储相关参数来缩小向量检索范围,从而提高索引准确性。在天气简报数据集上的实验表明,与原始RAG相比,NVRAG的忠实度(Faithfulness) 和准确率(AR) 更高,但牺牲了部分响应时间。该方法增强了系统处理复杂查询请求的能力。 2. 引言 本章节介绍了研究背景和问题。大语言模型(LLM)在许多领域已成熟应用,但在处理未预训练的数据库时,提取能力仍然不足。基于向量索引的RAG模型通过利用数据库索引来增强LLM从未训练数据中学习的能力。然而,RAG在处理具有强索引关联(如多键值查询)的问题时,准确性相对较低。这主要是因为RAG对多键值查询的优化能力不足。因此,本文提出一种基于文本转SQL(Text-to-SQL) 转换的创新方法,将用户自然语言查询转换为特定的数据库查询语句,旨在解决现有RAG模型在仅依赖向量数据库进行语义匹配时遇到的性能问题,特别是在索引和关联性挑战方面,从而提升整体查询性能和可靠性。 3. 文献综述 本章节分为两个主要部分,回顾了相关技术: * 3.1 检索增强生成(RAG):详细介绍了传统RAG模型的两阶段工作流程(检索阶段和生成阶段)。其核心是利用向量化技术进行语义匹配,并通过Top-K方法召回相关内容。文章指出了该标准框架的一个显著缺点:其匹配算法过度依赖问答对的索引和用户语句的相似性,导致其在处理涉及多个关联索引(如时间范围统计)的查询时难以提供精确答案。 * 3.2 文本转SQL与大语言模型:介绍了基于大模型微调的Text-to-SQL方法,它能够将自然语言查询转换为结构化的SQL语句,使用户能够以自然语言与数据库交互。文章指出,LLM在自然语言理解和生成方面表现出色,而专门针对代码训练的LLM(如CodeLLaMa)能够生成符合用户需求的代码。通过微调,LLM可以针对特定数据库结构进行优化。将Text-to-SQL集成到RAG的检索模块中,可以改善信息检索能力,解决多索引联合查询的挑战。 4. 方法论 本章节详细阐述了提出的非向量检索增强生成(NVRAG)模型的工作流程,该流程通过结合非向量数据库和Text-to-SQL来增强对复杂多键值关联查询的处理能力。 * 核心思想:在RAG存储向量数据的同时,将额外的元数据(如原始问答对、索引ID、显式信息如时间、数值等)存储在独立的非向量数据库中。当检测到用户输入包含SQL相关信息(如明确的时间范围)时,利用Text-to-SQL技术将用户查询转换为精确的SQL语句,在非向量数据库中进行针对性检索,从而缩小后续向量检索的范围。 * 4.1 检索模块:在构建问答对时,通过修改提示词,引导模型识别并显式标记出易于提取的关键元素(如时间信息),并将其与非向量数据库关联。当用户输入被分类为包含SQL信息时,经过预处理的查询会被Text-to-SQL模型转换为SQL语句,用于查询非向量数据库,获取一个经过筛选的、更相关的候选问答对集合,然后再在此范围内进行传统的向量相似性匹配。 * 4.2 生成模块:负责接收用户输入,并进行预处理(文本清洗、上下文管理、指代消解)和场景分类,以过滤出可能与显式数据相关的信息。然后,它将优化后的查询传递给检索模块。最后,将检索模块返回的Top-K相关结果与用户问题结合,输入生成式AI模型以产生最终答案。 5. 实验 本章节描述了为验证NVRAG模型有效性所设计的实验。 * 评估目标:比较原始RAG模型与NVRAG模型在时间信息提取方面的能力。 * 评估指标:采用RAGAS评估框架中的忠实度(Faithfulness) 和准确率(AR)。 * 实验设置:使用FastGPT平台部署并测试两个模型。 向量检索器使用PostgreSQL的PG Vector插件(HNSW索引),非向量数据使用MongoDB。 数据集:包含100条连续数据的天气简报数据集,涵盖日期、天气状况、建议等信息,最终生成1432个键值对。 Text-to-SQL模块:使用开源模型Chat2DB_sql_7B。 生成模型:使用OpenAI GPT-3.5-turbo。测试查询:由另一个LLM生成,要求必须包含时间信息(如日期范围或多日期比较),以确保测试时间相关查询。 6. 结果 本章节展示了实验的量化结果,并通过表格(表2)进行了清晰对比。 * 主要发现: 对于一般用户查询:两种模型的忠实度和准确率相近(RAG略高),但RAG的响应时间稍快(2.10秒 vs. 2.24秒)。 对于时间相关用户查询:NVRAG模型性能显著优于原始RAG。NVRAG的忠实度(0.85)和准确率(0.91)远高于RAG(0.32和0.46)。这证明了Text-to-SQL和非向量数据库在处理复杂时间范围查询上的有效性。 权衡:NVRAG的性能提升是以更长的响应时间为代价的(3.76秒 vs. 2.98秒),因为增加了SQL查询和多步骤检索操作。但作者认为,性能的大幅提升使得这种时间开销是可接受的。 7. 结论 本章节总结了全文的工作、贡献和未来方向。 * 总结:本文提出的NVRAG模型通过引入非向量数据库和Text-to-SQL技术,有效增强了RAG模型处理多索引关联复杂查询(尤其是时间范围查询)的能力。 * 优势:NVRAG在忠实度和准确率上表现更优,解决了传统RAG在复杂查询上的局限性。 * 代价:改进带来了响应时间的增加。 * 要求与未来工作:NVRAG对知识库文档的格式有一定要求(需要易于提取的结构化信息)。未来研究应专注于优化NVRAG的响应时间,并探索其在更广泛领域和数据集上的应用,以验证其通用性和可扩展性。 8. 参考文献 本章节列出了论文中引用的相关学术文献,涵盖了大型语言模型、检索增强生成、文本转SQL、评估方法等多个相关领域的研究,为本文的工作提供了理论和技术基础。
13分钟 ·30 - 生成式AI大模型结合知识库与AI Agent开展知识挖掘的探析
这篇论文《生成式AI大模型结合知识库与AI Agent开展知识挖掘的探析》主要探讨了如何利用生成式AI大模型(LLM),结合外部知识库和AI Agent技术,来革新情报领域中的知识挖掘工作。以下是论文的主要内容总结: 1. 研究目的与背景 * 目的:探索大模型结合知识库与AI Agent进行知识挖掘的方法、工具、技术框架和应用实践,为大模型在情报领域的专业化、场景化应用提供参考。 * 背景:以ChatGPT为代表的大模型展现出强大的语义理解和知识泛化能力,为知识挖掘(如信息检索、知识抽取、知识发现)带来了范式变革的可能。传统方法依赖人工深度参与,流程繁琐,而大模型有望提升全流程的自动化和智能化水平。 2. 核心论点 大模型不仅仅是执行单一任务的工具,更可以作为逻辑中枢,通过结合领域知识库(提供精准、最新的专业知识)和AI Agent(具备自主规划、调用工具的能力),自主地细分并完成复杂的知识挖掘任务,实现全流程的智能化。 3. 关键技术方法 * 大模型结合知识库:重点介绍了检索增强生成(RAG) 方法。RAG通过从外部知识库(如向量数据库)动态检索相关信息来辅助大模型生成答案,能有效减少大模型的“幻觉”问题,提高回答的准确性和相关性。论文还讨论了与文档知识库、关系型数据库和知识图谱结合的具体方法和挑战。 * 大模型驱动AI Agent:阐述了AI Agent的核心思想,即具备记忆、规划、工具使用和行动四大模块的智能系统。大模型作为其“大脑”,负责理解、规划和决策。论文介绍了实现Agent的关键工具,如LangChain、AutoGen等。 4. 实验与应用验证 论文通过三个实验验证了所提方法的有效性: * 实验1(基础RAG):基于RAG构建本地文档知识库(智能芯片领域文献),进行创新情报问答。结果显示,结合知识库的答案比单纯使用大模型更具体、准确,且能提供出处。 * 实验2(AI Agent全流程自动化):使用AutoGen框架构建多智能体系统,成功实现了从arXiv自动检索特定时段芯片设计文献、总结研究贡献、抽取技术指标的全流程自动化任务。 * 实验3(基于知识图谱的进阶Agent):构建了量子计算领域的技术指标知识图谱,并开发了基于知识图谱RAG的AI Agent。该Agent能够理解用户关于技术先进性的复杂查询,自动检索知识图谱并进行推理分析,给出准确答案。 5. 结论与展望 * 结论:大模型作为逻辑中枢,结合知识库与AI Agent,不仅能处理细分任务,更具备使知识挖掘全流程自主化、智能化的潜力。实现有效应用的关键在于对情报任务进行深入细分,并准备相应的知识库和Agent。 * 不足与展望:当前研究仍是初步探索,任务场景较单一,缺乏系统化评估。未来研究应更关注提示工程的策略本质(这是情报学擅长的问题),并随着算力成本的下降,深入探索与AI更深度融合的知识挖掘与情报研究新范式。 总之,该论文系统性地提出并验证了一个以生成式AI大模型为核心,整合知识库与AI Agent技术,以实现智能化、自动化知识挖掘的新技术框架和应用路径。 根据提供的文章《生成式AI大模型结合知识库与AI Agent开展知识挖掘的探析》,以下是对其每一章节内容的详细介绍: 文章概览 * 标题:生成式AI大模型结合知识库与AI Agent开展知识挖掘的探析 * 作者:赵浜、曹树金 * 来源:《图书情报知识》2025年第42卷第4期 * 核心主题:探讨如何将生成式AI大模型、知识库和AI Agent三者结合,以革新情报领域的知识挖掘工作,实现全流程的自动化与智能化。 第一章:摘要 本章概括了全文的研究目的、方法、主要结论和创新价值。 * 目的/意义:探索大模型结合知识库与AI Agent进行知识挖掘的方法、工具、技术框架与应用实践,为情报领域的大模型专业化、场景化应用提供参考。 * 研究设计/方法:系统调研相关技术与工具,并针对科技文献进行知识挖掘测试。 * 结论/发现:大模型作为逻辑中枢,结合知识库与AI Agent,能够自主细分并智能化地完成知识挖掘任务。 * 创新/价值:从概念、方法、技术框架到应用,系统性地探析了基于大模型的智能知识挖掘手段,为未来情报实践与研究提供启示。 第二章:引言 本章阐述了研究的背景和动机。 * 背景:以ChatGPT为代表的生成式AI大模型正在深刻改变人类知识的解构与重构方式,并在信息检索、知识抽取等领域展现出巨大潜力。 * 核心观点:大模型强大的语义理解和交互能力,使其能够融合外部知识并充当AI Agent的“大脑”,这为情报领域的知识挖掘带来了范式变革的机遇。 * 研究目标:探索三者结合的方法、工具、框架与实践,推动大模型在情报领域的专业化应用。 第三章:大模型赋能知识挖掘 本章分析了知识挖掘的传统方法,并阐述大模型如何为其赋能。 * 3.1 传统方法:数据挖掘:利用数据库技术和统计机器学习算法(如分类、聚类)从数据中提取模式。 领域知识库构建:通过文本挖掘和NLP技术(如基于规则或深度学习的方法)从非结构化文本中抽取知识单元。 知识图谱构建:以语义三元组形式存储实体和关系,支持更复杂的知识推理任务。 * 3.2 大模型赋能原理:能力基础:大模型具备强大的语义理解、上下文学习、指令遵循和逐步推理能力,拥有广泛的知识基础。 角色定位:大模型并非直接替代传统方法,而是通过其通用性和泛化能力,优化和重构工作流程,提升自动化与智能化水平。它可以在认知、应用(直接执行任务)和执行(生成代码、查询语句)三个层面与传统方法关联。 对情报领域的影响:使知识挖掘的对象更细、语料更广、领域更宽、方法更丰富,并拓展了研究视角和人才培养重点。 第四章:大模型结合知识库的方法与工具 本章详细介绍了大模型与知识库结合的关键技术与实践案例。 * 4.1 检索增强生成(RAG):为解决大模型的“幻觉”问题,RAG通过从外部知识源(如向量数据库)动态检索相关信息来辅助大模型生成答案,提高准确性和相关性。相比微调,RAG更轻量、灵活。 * 4.2 思维链与开发工具:介绍了利用思维链(CoT)进行推理的思路,以及LangChain这一热门开发框架,它天然支持RAG的构建,将流程分解为索引、检索与生成两部分。 * 4.3 与各类知识库的结合:向量数据库:是实现RAG的关键,用于存储和检索文本向量(嵌入)。介绍了Faiss、Milvus等主流方案。 文档知识库:是RAG的主要应用场景,已有Langchain-Chatchat等成熟解决方案。 关系型/非关系型数据库:大模型可通过生成SQL查询与数据库交互,进而进行数据分析,但复杂查询仍是挑战。 知识图谱:结合方式多样,例如大模型生成查询语句(如SPARQL)从图谱中检索知识,或与图谱协同推理(Think-on-Graph)。 * 4.4 应用案例:科技创新情报挖掘:通过部署基于RAG的问答应用(使用Qwen-7B模型和智能芯片文献知识库),演示了在“芯片功耗创新”查询任务上,结合知识库的答案(具体、有出处)远优于仅使用大模型的答案(笼统、宽泛)。 第五章:大模型结合AI Agent开展知识挖掘的方法与框架 本章将AI Agent引入框架,探讨更高级的自动化知识挖掘。 * 5.1 AI Agent核心思想:AI Agent是以大模型为“大脑”,具备记忆(知识库)、规划(任务分解与策略制定)、工具使用(调用API等)和行动(执行决策)四大模块的自主系统。 * 5.2 关键技术工具:介绍了Fastchat(本地模型部署与API化)、ToolLLM(赋予大模型调用真实API的能力)、AutoGen(微软开源的多智能体协作框架)等工具。 * 5.3 技术框架:提出了一个综合框架,其中大模型作为中枢,LangChain/AutoGen负责规划,知识库提供记忆,外部工具被调用以完成任务。 * 5.4 应用案例一:全流程自动化创新情报发现:使用AutoGen构建多智能体小组,成功自动化完成了从arXiv检索“芯片设计”文献、总结贡献到抽取技术指标的全流程,展示了AI Agent对复杂任务的自主分解与执行能力。 * 5.5 应用案例二:基于知识图谱RAG的Agent进行技术先进性挖掘:在构建量子计算领域技术指标知识图谱的基础上,开发了基于知识图谱RAG的AI Agent。测试表明,Agent能理解用户关于“量子比特相干时间最先进系统”的查询,自动检索图谱并推理出正确答案,展示了结合知识图谱后更强大的结构化知识检索与推理能力。 第六章:总结与展望 本章总结了研究发现,并指出了未来方向。 * 主要结论:大模型结合知识库与AI Agent能实现知识挖掘任务的全流程自主化与智能化。 大模型在此模式中的核心角色是逻辑中枢,连接领域知识与工具,其专业化能力因此大幅增强。 实现有效应用的关键在于对情报任务场景进行深入细分,并配备相应的知识库和Agent。 * 研究不足:承认当前研究仅是初步的应用性探索,任务场景较单一,缺乏系统化评估,也未提出新的理论框架。 * 未来展望:研究重点:提示工程(及其智能化拓展如RAG、Agent)本质上是信息组织策略问题,非常适合情报学深入研究。应关注大模型与知识库/Agent交互机制的优化。 趋势:随着算力成本下降,与AI的深度融合将成为必然。知识挖掘等情报工作的效率将空前提升,未来的研究重点将转向如何智能地管理AI的运作。 对情报学的意义:情报学的研究和人才培养需积极应对这场变革,关注AI管理、人机协同等新课题。 其他部分 * 参考文献:列出了本文引用的相关学术文献。 * 支撑数据:说明了本文实验相关的数据、代码和测试材料由作者存储并提供。 综上所述,本文系统性地构建了一个由大模型驱动、知识库支撑、AI Agent执行的智能知识挖掘框架,并通过具体案例验证了其在情报领域,特别是科技创新情报挖掘中的应用潜力,为后续研究和实践提供了清晰的路径参考。
13分钟 ·140 - 基于 RAG 架构的智能知识库设计与应用研究
根据提供的文章,该论文的主要内容总结如下: 1. 研究背景与问题: 文章指出,传统知识库在知识更新、语义理解和检索精准性方面存在不足,难以满足动态化、智能化的现代知识应用需求。 2. 核心解决方案: 研究提出基于检索增强生成(RAG) 技术来构建智能知识库。RAG架构通过结合信息检索与文本生成,使系统能够动态检索外部知识并基于此生成回答,从而提升答案的准确性、相关性和时效性。 3. 系统设计与技术实现: * 设计原则:涉及数据采集、知识组织、存储管理和检索服务等环节。 * 关键技术栈:框架:采用 FastGPT 作为基础问答系统框架,用于数据处理和工作流编排。 向量模型:使用 M3E 模型将文本转换为向量,实现语义检索。 生成模型:采用 ChatGLM3 作为大语言模型,负责结合检索到的上下文生成最终答案。 * 工作流程:主要包括知识库构建(文档分块、向量化存储)、问题检索(向量相似度搜索)和答案生成(LLM结合上下文生成回答)三个核心部分。 4. 应用研究: 论文探讨了基于RAG的智能知识库在智能问答系统(如教育、医疗领域)和知识图谱构建(自动化知识抽取与更新)中的具体应用价值。 5. 实验验证: 研究以《大学计算机基础》课程资料为例构建知识库进行实验。结果表明,基于RAG架构的系统在检索准确率、答案生成质量和响应速度方面表现良好,验证了其有效性。 6. 结论与展望: 文章总结认为,基于RAG架构的智能知识库为知识管理提供了一种高效的解决方案,在企业和教育等领域具有广泛的应用前景,能推动知识服务向智能化、个性化方向发展。 根据提供的文章《基于 RAG 架构的智能知识库设计与应用研究》,其章节内容详细介绍如下: 摘要 概述了传统知识库在知识更新、语义理解和检索精准性方面的不足,提出了基于检索增强生成(RAG)技术来提升知识库的检索精准性和生成能力。文章围绕RAG架构探讨了智能知识库的设计原则、适用场景和构建过程,并指出其在企业和教育等领域具有广泛的应用前景。 0 引言 阐述了智能知识库在现代信息化中的重要性,以及传统知识库面临的挑战。提出了通过融合RAG技术(结合FastGPT框架、ChatGLM3模型和M3E向量检索模型)来构建智能知识库系统,旨在实现自动化梳理、动态问答与个性化推荐,为智能化发展提供新思路。 1 RAG 架构的基本概念 解释了RAG是一种将信息检索与文本生成相结合的人工智能架构。其核心是通过在生成回答前,动态从外部知识库中检索相关信息,从而提升生成内容的准确性、可控性和知识丰富度,为智能问答和知识管理提供高效解决方案。 2 智能知识库的设计 * 2.1 智能知识库设计的基本原则:指出知识库构建是一个涉及数据采集、知识组织、存储管理和检索服务的系统化过程,强调通过对多源异构数据的规范化和语义化处理来奠定高效检索的基础。 * 2.2 智能知识库的数据结构设计:详细描述了基于RAG的问答系统的三个核心部分(知识库构建、问题检索、答案生成)及其工作流程。具体步骤包括:文档分块与向量化、查询向量检索相似上下文、将上下文与问题结合并交由大语言模型生成最终答案。 * 2.3 智能知识库的数据管理与查询处理:介绍了利用FastGPT框架来快速构建RAG问答系统。说明了其工作流程:将知识内容分割并向量化存储;用户提问时,将问题向量化并进行相似度搜索;将检索到的相关内容作为上下文传递给语言模型以生成答案。 3 基于RAG架构的智能知识库应用研究 * 3.1 智能问答系统的应用:以医疗领域为例,说明了基于RAG的智能知识库如何通过理解意图、精准检索和生成回答,为动态、个性化的智能问答提供解决方案。 * 3.2 在知识图谱构建中的应用:阐述了RAG架构如何辅助知识图谱的构建与更新,包括从非结构化文本中自动化抽取知识、利用语义匹配补全知识图谱、以及通过持续检索实现知识的动态更新。 4 实验与分析 * 4.1 实验环境与数据集:说明实验以《大学计算机基础》课程的相关教材和常见问题作为数据集,导入FastGPT进行知识库构建。 * 4.2 实验方法与步骤:4.2.1 向量化模型加载:采用M3E模型作为文本向量检索模型,并集成到FastGPT框架中。 4.2.2 向量数据入库:使用PostgreSQL数据库及其向量扩展来存储文本经过M3E模型转换后的语义向量。 4.2.3 大语言模型 ChatGLM3 构建:将ChatGLM3模型作为生成核心,通过JSON配置文件进行加载和参数管理。 4.2.4 基于向量知识库的知识检索:描述了将文本分段向量化后存储,并通过向量相似度搜索实现语义检索的机制。 4.2.5 提示词模板构造:强调了提示词模板对于引导模型生成高质量回答的重要性,并展示了包含背景知识引用、对话要求等部分的模板示例。 * 4.3 实验结果:指出基于RAG架构的智能知识库在实验中表现出较高的检索准确率、优质的答案生成能力和较快的响应速度,提升了系统的智能化水平和用户体验。 5 结语 总结了基于RAG架构的智能知识库通过整合向量检索与生成式问答技术,为知识管理提供高效解决方案。重申了以FastGPT、M3E和ChatGLM3为核心构建的技术流程及其在企业培训、高校教学等领域的应用价值,展望了其推动行业信息化向智能化、个性化方向发展的潜力。
9分钟 ·160 - 基于大语言模型(LLM)与检索增强生成(RAG)融合机制的面向编辑辅助决策的可解释审稿人推荐方法
这篇题为《基于大语言模型(LLM)与检索增强生成(RAG)融合机制的面向编辑辅助决策的可解释审稿人推荐方法》的论文,其主要内容总结如下: 1. 研究背景与问题 * 背景:在科技期刊稿件量增长的背景下,快速、精准地找到合适的审稿人对保证评审质量和出版效率至关重要。 * 现有方法不足:传统的审稿人推荐方法(如基于协同过滤或基于内容语义匹配的方法)存在局限性,包括:难以处理跨学科或新兴主题、可能导致审稿人负载不均衡、以及推荐结果缺乏可解释性。直接使用大语言模型(LLM)则存在“幻觉”(生成虚假信息)和知识更新滞后的问题。 2. 提出方法 * 核心方案:为解决上述问题,本研究设计并实现了一个智能审稿人推荐系统(IRRS)。该系统创新性地融合了大语言模型(LLM)与检索增强生成(RAG)技术。 * 核心思路:利用RAG技术引入外部知识库(本研究使用Web of Science文献元数据构建),为LLM提供准确、最新的学术信息约束,从而减少幻觉。同时,通过精心设计的双层提示词框架,引导LLM基于检索到的信息生成候选审稿人名单及可解释的推荐理由。 3. 系统设计与流程 * 系统架构:IRRS包含三层:数据层:负责采集和清洗WoS元数据。 知识表征层:使用关系数据库和向量数据库共同存储和管理数据,其中向量数据库用于高效的语义相似度检索。 智能推荐层:核心流程包括:将待审稿件向量化 → 从向量库中检索语义相似的Top-N文献 → 提取这些文献的作者作为候选审稿人 → 进行利益冲突检测 → 利用双层提示词框架引导LLM生成排序后的推荐列表及理由。 4. 实验与效果评估 * 实验设置:以期刊 Intelligent Computing 2025年的20篇已发表论文为测试样本,将IRRS的推荐结果与期刊原使用的Scopus推荐系统进行对比。 * 评估结果:语义匹配精度:IRRS推荐的首位审稿人与稿件的平均语义相似度(0.688)高于Scopus系统(0.596),且结果更稳定。 推荐策略差异:Scopus倾向于推荐高h-index的资深学者,而IRRS的推荐名单中包含更多学术影响力指标多样的学者,有助于发现新晋专家。 推荐理由质量:通过专家评审,IRRS生成的推荐理由在主题契合度、事实准确性、可解释性方面均获得良好评价(均值≥4.0/5.0),多样性方面尚有提升空间。 5. 结论与展望 * 结论:本研究提出的LLM与RAG融合框架,在不改变底层模型的前提下,通过外部知识库和提示词工程,有效提升了审稿人推荐的语义匹配精度和结果可解释性。系统具有模块化、易扩展、低部署门槛的特点,便于期刊编辑使用。 * 展望:未来可在更多学科领域验证其适用性,并在真实编辑流程中跟踪其实际效果(如审稿邀请接受率),以进一步优化系统,为科技期刊的数字化转型提供实用的决策支持工具。 根据提供的文章《基于大语言模型(LLM)与检索增强生成(RAG)融合机制的面向编辑辅助决策的可解释审稿人推荐方法》,其正文部分主要包含以下几个章节,现将每一章节的内容详细介绍如下: 1. 引言(未明确标出“引言”,但文章开头至“1 数据来源与研究方法”之前的内容承担此功能) 本章节阐述了研究的背景、意义、现有方法的局限以及本研究的创新点。 * 背景与问题:指出在科技期刊同行评审中,高效、精准地寻找审稿人是关键环节。自动化审稿人推荐早期主要采用基于历史评审记录的协同过滤方法,但该方法存在处理新主题、交叉学科时匹配难,以及可能导致审稿人负载不均衡的问题。 * 现有方法演进:介绍了从基于内容(如LSI、LDA、TF-IDF)到基于深度学习嵌入技术(如Word2Vec、Doc2Vec),再到利用大语言模型(LLM) 进行语义理解和推荐理由生成的技术发展路径。 * LLM应用的挑战与解决方案:指出直接应用LLM面临成本高、存在“幻觉”和知识滞后等问题。提出结合检索增强生成(RAG) 技术,通过引入外部知识库来增强LLM的可靠性和实时性,是当前有前景的方向。 * 本研究目标:提出构建融合LLM与RAG的智能审稿人推荐系统(IRRS),旨在提升语义匹配精度和推荐结果的可解释性,并为编辑决策提供支持。 2. 数据来源与研究方法 本章节详细说明了研究的数据基础、案例选择以及评估方法。 * 2.1 概念界定:明确了研究场景是“借助系统推荐”进行稿件分配,旨在验证IRRS框架的可行性与解释能力,而非进行大规模统计推断。 * 2.2 数据来源:研究样本:以《Intelligent Computing》期刊2025年已出版的20篇论文作为测试案例。 外部知识库:基于Web of Science (WoS)数据库,选取近10年计算机科学及相关交叉领域的文献元数据(作者、标题、摘要、关键词等)构建。 * 2.3 研究方法:对比系统:选择期刊系统搭载的Scopus审稿人推荐系统作为对比基准。 技术路线差异:指出Scopus基于数据库检索与统计特征分析;而IRRS采用BGE-M3嵌入模型进行语义向量化,结合向量检索与LLM生成排序。 评估方案:由于Scopus无可解释性输出,对比主要集中在语义匹配效果。对于IRRS的推荐理由质量,邀请了5名评审员(期刊编辑和领域专家)从四个维度(主题契合度、事实准确性、可解释性、多样性)进行人工评分,并引入了“自信度”指标进行加权计算。 3. 系统设计思路 本章节是文章的核心,详细阐述了IRRS系统的整体架构和各个模块的设计。 * 整体架构:IRRS分为三层:数据层:负责WoS元数据的采集、清洗(去重、作者/机构标准化、语义信息整理)与融合。 知识表征层:由两个数据库构成。关系数据库:存储结构化的实体(作者、论文、机构等)及它们之间的关联。 向量数据库:存储文献的标量字段(标题、摘要等文本)和对应的向量字段(文本的语义向量),作为RAG的外部知识库。 智能推荐层:实现核心推荐流程,包含五个组件:稿件特征向量化:将稿件标题、摘要、关键词分别编码为向量。 相似文献检索:采用“粗召回+精排序”两阶段策略,基于余弦相似度从向量库中找出与稿件最相关的Top-N篇文献。 候选审稿人信息获取:从相关文献中提取作者信息,并补充其学术指标(如h-index)。 利益冲突检测:自动检测候选人与稿件作者是否存在近期合作或机构关联。 提示词模板构建:设计双层提示词框架(系统级和用户级),引导LLM基于检索到的外部知识,生成排序后的审稿人名单及推荐理由。 4. 效果分析 本章节通过实验对比和人工评估,展示了IRRS系统的性能。 * 4.1 语义匹配效果分析:与Scopus对比,IRRS推荐的审稿人与稿件的综合语义相似度均值更高(0.688 vs. 0.596),且波动更小,表明匹配精度和稳定性更好。 在审稿人学术影响力分布上,Scopus更倾向于推荐高h-index的资深学者,而IRRS能推荐更多h-index相对较低的学者,有助于发现新晋力量。 * 4.2 生成质量效果分析:对IRRS生成的推荐理由进行人工评估,四个维度的加权平均分均较高(主题契合度4.17、事实准确性4.05、可解释性4.05、多样性3.64),表明推荐理由整体质量良好,尤其在主题匹配和事实准确性上表现突出。 提供了具体的推荐理由示例(表2),展示了系统如何从研究领域匹配度、近期活跃度、学术影响力等方面生成解释性文本。 5. 结束语 本章节总结了研究的主要贡献、实践意义,并展望了未来工作。 * 研究总结:重申IRRS框架有效提升了审稿人推荐的语义匹配精度和结果可解释性,生成的推荐理由能为编辑提供透明的决策依据。 * 实践价值:IRRS可作为独立的辅助决策工具,降低编辑筛选审稿人的时间成本。其模块化设计(可替换LLM、知识库、提示词)使得系统易于适配不同学科期刊,无需重新训练模型,降低了部署门槛。 * 未来展望:提出可从两方面深化研究:在真实编辑流程中进行长期跟踪,评估审稿人邀请接受率、审稿周期等实际效果指标。 在更多学科领域(如医学、人文社科)进行验证,提升系统的泛化能力和学科适用性。
14分钟 ·140 - RAGPerf:检索增强生成系统端到端基准评测框架
根据提供的论文《RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems》,其主要内容总结如下: 1. 核心目标与动机 论文旨在解决当前缺乏一个能够全面、可配置地评估检索增强生成(RAG)系统端到端性能和质量的基准测试框架的问题。现有基准大多只关注语义质量或孤立组件的性能,无法捕捉真实部署中全流程的系统行为、资源竞争和配置权衡。因此,作者提出了RAGPerf框架。 2. RAGPerf框架的核心设计 RAGPerf是一个模块化、可扩展的端到端基准测试框架,其主要设计特点包括: * 模块化流水线:将RAG工作流解耦为独立的、可配置的组件,包括数据嵌入(Embedding)、索引(Indexing)、检索(Retrieval)、重排序(Reranking)和生成(Generation)。 * 可配置性:允许用户灵活配置每个组件的核心参数(如嵌入模型、向量数据库类型、索引方法、LLM模型、批处理大小等),并研究它们对端到端性能和查询质量的影响。 * 真实工作负载生成:内置工作负载生成器,支持多种数据集(文本、PDF、代码、音频)、不同的查询/更新比例、查询分布(均匀分布、Zipfian分布),以模拟真实场景中知识库的动态更新和访问模式。 * 自动化指标收集:性能指标:端到端查询吞吐量/延迟、主机/GPU内存占用、CPU/GPU利用率、I/O吞吐量等。 质量指标:通过集成Ragas框架,自动评估上下文召回率(Context Recall)、查询准确性(Query Accuracy)和事实一致性(Factual Consistency)。 * 低开销分析:采用独立的系统性能监控器,在引入可忽略性能开销(论文评估为~0.11%)的情况下,进行细粒度的系统和组件级性能剖析。 3. 实现与支持 * 实现语言:Python。 * 支持范围:数据集:Wikipedia、ArXiv、GitHub代码、People‘s Speech音频等。 模型:多种嵌入模型(如all-MiniLM-L6-v2)、重排序模型(如BGE)和生成LLM(如Qwen、Llama系列)。 向量数据库:LanceDB、Milvus、Qdrant、Chroma、Elasticsearch。 多模态支持:提供针对PDF/图像(OCR或ColPali直接编码)和音频(ASR转录)的专用处理流程。 4. 评估验证 论文通过一系列实验证明了RAGPerf的能力: * 端到端性能剖析:识别不同模态(文本、PDF、音频)RAG流水线的瓶颈(如文本流水线中LLM生成是主要瓶颈)。 * 资源利用分析:揭示不同阶段对GPU计算、CPU、主机内存和I/O等资源的需求差异。 * 准确性评估:展示生成模型的能力(而非向量数据库)对最终答案质量起主导作用,且高检索召回率不一定能转化为高答案准确性。 * 更新操作影响:量化了知识库持续更新对查询延迟和准确性的影响,以及临时平面索引(flat index)策略的权衡。 * 配置敏感性分析:分析了批处理大小、嵌入维度、索引方法等参数对性能和资源消耗的影响,为系统调优提供数据支持。 5. 结论与贡献 RAGPerf填补了RAG系统端到端基准测试的空白。它帮助开发者和研究人员理解复杂的RAG流水线在不同配置和工作负载下的系统行为与性能瓶颈,从而做出数据驱动的优化和部署决策。论文已将RAGPerf开源。 根据提供的文章《RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems》,以下是各章节内容的详细介绍: 摘要 本文介绍了RAGPerf的设计与实现,这是一个用于表征RAG(检索增强生成)管道系统行为的端到端基准测试框架。为了便于详细分析和细粒度性能剖析,RAGPerf将RAG工作流解耦为几个模块化组件:嵌入、索引、检索、重排序和生成。它允许用户灵活配置每个组件的核心参数,并检查它们对端到端查询性能和质量的影响。RAGPerf包含一个工作负载生成器,通过支持多样化的数据集、不同的检索与更新比例以及查询分布来模拟真实场景。它还支持不同的嵌入模型、主流向量数据库以及用于内容生成的不同大语言模型。该框架自动化收集性能指标和准确性指标。通过一系列综合实验展示了其能力,并在GitHub上开源了代码库。评估表明,RAGPerf带来的性能开销可以忽略不计。 1. 引言 本章阐述了大型语言模型(LLM)的局限性,特别是在需要领域特定知识或私有数据的场景下。检索增强生成(RAG)技术被提出以解决此问题。然而,部署RAG管道时,理解其系统瓶颈和设计权衡至关重要。由于整个RAG管道计算栈的复杂性,研究其在实际部署场景下的性能影响和查询质量非常困难且耗时。现有的RAG基准测试大多关注特定应用的语义指标,很少研究RAG管道的性能行为,且缺乏灵活性。受YCSB等云服务基准框架的启发,本文提出了RAGPerf,旨在为RAG生态系统提供一个专用的端到端基准测试框架。 2. 背景与动机 本章分为三个小节: * 2.1 RAG-based AI系统架构:详细描述了典型RAG系统的三个阶段:索引(将原始数据分块、嵌入并存入向量数据库)、检索(将用户查询编码为向量并进行相似性搜索,可能包括重排序步骤)和生成(将查询和检索到的上下文组合成提示,交由LLM生成最终响应)。 * 2.2 RAG应用:总结了RAG在不同领域的流行应用,包括对话式AI、企业智能(如法律、金融、医疗)和多模态语义搜索(如视频、图像、会议摘要)。这些应用对底层硬件资源的需求和瓶颈各不相同。 * 2.3 RAG系统基准测试:分析了现有RAG基准测试的不足:要么只关注语义指标而忽略系统效率,要么只评估单个组件(如向量数据库或LLM),无法捕捉全集成管道中的运行时性能干扰和资源争用,且通常缺乏可配置性。这构成了开发RAGPerf的动机。 3. 设计与实现 本章详细阐述了RAGPerf的设计目标和具体实现: * 3.1 RAGPerf的目标:包括端到端评估、模块化与易用性、低开销剖析、工作负载多样性以及可扩展性和可移植性。 * 3.2 工作负载生成器:为了模拟真实世界知识库的动态更新,RAGPerf生成并发的读写请求。它支持四种基本操作:查询、插入、更新和删除。用户可以配置操作的发生概率和访问分布(均匀分布或Zipfian分布)。对于更新操作,RAGPerf使用基于LLM的生成模块来合成事实更新及其对应的问答对,以验证更新后的知识库。 * 3.3 可配置的RAG管道:RAGPerf将管道分解为可独立配置的模块:嵌入:支持不同的分块策略(固定长度、基于分隔符、基于语义)、文档格式处理(纯文本提取或OCR)以及多种嵌入模型(包括多模态模型)。用户可以配置硬件资源分配。 向量数据库与索引:通过DBInstance抽象层支持多种向量数据库。允许配置不同的索引方法、量化方案和更新策略(如使用临时平面索引来吸收增量更新)。 重排序:通过BaseReranker抽象层支持不同的重排序模型和策略,并允许配置初始检索深度。 生成:使用vLLM作为默认的LLM后端,支持多种LLM和并行策略(数据并行、张量并行、流水线并行)。 * 3.4 性能与质量指标:性能指标:通过一个解耦的资源监控器收集细粒度的硬件资源利用率(CPU/GPU利用率、内存占用、I/O吞吐量)和端到端性能指标(延迟、吞吐量)。 质量指标:集成Ragas框架,在负载执行后评估生成质量,包括上下文召回率、事实一致性和查询准确性。 * 3.5 RAGPerf实现:框架使用Python实现,基于HuggingFace生态系统,支持多种向量数据库,使用vLLM作为LLM服务后端,并利用容器化工具管理依赖。监控子系统实现为一个多线程守护进程。 4. 基准测试工作负载 本章定义了RAGPerf默认包含的一组代表性工作负载: * 4.1 数据集:涵盖多种模态和结构复杂性,包括Wikipedia(文本)、ArXiv(PDF)、GitHub代码和The People‘s Speech(音频)。 * 4.2 模型:支持涵盖嵌入、重排序和生成整个管道的综合模型集,包括通用模型和针对编码、数学、视觉理解等领域的专用模型。 * 4.3 向量数据库:支持LanceDB、Milvus、Qdrant、Chroma和Elasticsearch,并支持多种索引方法。 * 4.4 多模态检索:为视觉和音频数据实现了独立的默认处理管道,例如使用OCR或直接视觉嵌入处理PDF/图像,使用ASR转录处理音频。 5. 评估 本章通过实验展示了RAGPerf的能力: * 5.1 实验设置:描述了测试平台的硬件、软件和数据集配置。 * 5.2 端到端性能:对文本和PDF管道进行了延迟分解分析。结果显示,对于文本查询,LLM生成是主要瓶颈;对于PDF管道,重排序可能成为主导;索引阶段,格式转换(如OCR)和数据库插入是主要开销来源。 * 5.3 资源利用率分解:展示了RAGPerf细粒度剖析资源使用的能力。不同阶段瓶颈不同:嵌入和生成阶段受GPU计算限制,检索和索引构建阶段CPU利用率高,插入阶段主机内存和磁盘I/O成为瓶颈。 * 5.4 准确性评估:评估了不同配置下的RAG质量。发现整体质量主要由生成模型决定,而非向量数据库。同时指出,高上下文召回率并不总能保证高准确性,因为小模型可能缺乏有效利用检索上下文的能力。 * 5.5 更新操作:评估了在持续文档更新下的性能。展示了使用临时平面索引可以在保证数据新鲜度(提高准确性)和查询延迟增长之间的权衡,以及更新分布(Zipfian vs 均匀)对性能的影响。 * 5.6 多样化资源配置的影响:量化了不同系统资源配置(CPU核心数、主机内存、GPU内存)对RAG性能的影响。发现GPU内存是主要硬件瓶颈,主机内存不足会严重降低吞吐量,而CPU核心数影响相对较小。 * 5.7 敏感性分析:分析了关键管道参数的影响,包括批处理大小、嵌入维度和向量数据库索引类型。展示了这些参数在吞吐量、内存使用和检索质量之间的权衡。 * 5.8 开销分析:表明RAGPerf的剖析功能引入的开销可以忽略不计(仅增加约0.11%的迭代时间),且自身资源消耗极低。 6. 相关工作 本章将相关工作分为三类: * RAG基准测试:回顾了专注于语义质量评估或单个组件性能评估的现有基准,指出它们与RAGPerf的端到端、可配置、系统级评估定位不同。 * RAG系统优化:概述了旨在优化RAG系统性能的研究工作,指出RAGPerf可以作为一个促进此类优化的易用框架。 * RAG扩展:提到了扩展RAG范式的新机制,并指出RAGPerf的模块化设计可以支持此类扩展。 7. 结论 总结了RAGPerf作为一个端到端RAG管道基准测试框架的价值,它能够帮助开发者识别性能瓶颈、探索设计权衡,并以可忽略的开销提供详细的系统剖析。
8分钟 ·20 - 预上下文生成:提升生成式AI代码生成效率的关键
这篇题为《预上下文生成:提升生成式AI代码生成效率的关键》的论文,核心论点是:生成式AI(特别是大语言模型)在代码生成任务中,因其逐字符(token-by-token)的自回归生成机制,在面临大规模、复杂代码库时,若每次都需实时处理全部上下文,将导致严重的效率瓶颈。为解决此问题,报告系统性地提出了以 “预上下文生成” 为核心的工程化解决方案。 论文的主要内容可总结如下: 1. 核心问题分析 * 效率瓶颈:LLM的逐字符生成方式及标准注意力机制的二次方计算复杂度,使得实时处理大型代码库上下文成本高昂,导致生成速度慢、资源消耗大。 * 上下文限制:有限的上下文窗口使模型难以捕捉代码中的远程依赖关系,影响生成代码的质量和准确性。 * 数据挑战:海量且质量参差不齐的文档和代码库,进一步加剧了即时处理的困难和输出结果的不确定性。 2. 核心解决方案:预上下文生成 * 核心理念:将必要、常用的上下文信息(如项目结构、API文档、编码规范)预先处理、结构化并存储,在代码生成时进行高效检索和利用,避免重复的实时计算。 * 基础方法:检索增强生成(RAG) 是实现预上下文生成的 foundational 方法。它通过外部知识库的索引与检索,为LLM提供相关的预生成上下文,从而提升生成效率和质量。 * 高级优化:报告详细阐述了超越基础RAG的高级技术,包括:预检索优化:如代码语义分块、添加元数据、使用LLM提高信息密度。 精密检索策略:如混合搜索、查询路由、图搜索。 后检索优化:如重排序、上下文蒸馏、纠正性RAG(CRAG)以过滤低质量内容。 生成优化:如思维链提示、自适应RAG。 3. 补充与替代技术 * 缓存与预计算:利用KV缓存、更高级别的上下文缓存(如Gemini上下文缓存)以及缓存增强生成(CAG) 来存储和复用预计算的状态,进一步提升效率。 * 模型架构优化:探讨了如Latte、Fast Multipole Attention等旨在降低Transformer计算复杂度的新架构,以及知识蒸馏技术,用于创建更小巧、高效的领域特定代码模型。 * 系统架构:强调了构建以预上下文为核心的可扩展AI系统架构的重要性,包括模块化设计、数据处理流水线,并介绍了动态知识图谱作为管理复杂代码上下文的先进形式。 4. 实践案例 * 报告分析了DeepWiki、Context7和DeepWiki-Open等实际系统,展示了预上下文生成(主要通过RAG架构)在将代码库转换为交互式知识库、为AI编码助手提供精准上下文等方面的具体应用,验证了其有效性。 5. 综合建议与未来展望 * 报告最后为构建高性能AI代码生成系统提出了综合建议,强调需根据场景(动态/静态代码库、资源限制等)混合搭配RAG、微调、缓存、蒸馏等技术。 * 提出了管理数据质量、减轻幻觉、保障安全与知识产权的最佳实践。 * 展望了未来趋势,如更深度的知识图谱集成、自我改进系统、多模态上下文以及形式化验证等。 总之,论文主张通过工程化的“预上下文生成”策略,将AI代码生成从依赖即时上下文处理的模型,转向集成了智能化上下文预生成、管理和高效检索的情境感知系统,从而实现显著的效率与质量提升。 以下是报告各章节的详细内容介绍: I. 瓶颈解析:理解缺乏预上下文时生成式AI在代码生成中的低效性 本章深入剖析了问题的根源。首先,它指出生成式AI(特别是LLM)固有的自回归、逐字符生成机制是效率低下的核心。标准Transformer的注意力机制具有二次方计算复杂度,处理长代码序列成本高昂。其次,海量且质量参差不齐的文档和代码库给即时处理带来巨大挑战,可能导致模型从低质量样本中学习,产生不安全或有缺陷的代码。最后,本章强调高质量的上下文理解对于生成正确、相关的代码至关重要,而缺乏预生成机制会导致模型重复计算、丢失远程依赖关系,并可能产生“幻觉”。 II. 检索增强生成(RAG):实现预上下文生成的foundational方法 本章将RAG定位为实现预上下文生成的基础方法。它详细阐述了RAG的核心机制: 1. 数据准备与分块:将源代码和文档进行预处理和分块,特别强调了针对代码的语义分块(按函数、类等自然边界分割)以保持上下文完整性。 2. 嵌入与向量存储:使用嵌入模型将文本/代码块转换为向量,并存储在向量数据库中,以实现基于语义相似性的高效检索。 3. 检索与生成:根据用户查询检索最相关的预生成上下文块,并将其注入提示中供LLM生成最终代码。 本章还重点讨论了上下文充分性的重要性,并引用了一个关键表格,展示不同LLM在预生成上下文“充分”与“不足”时的性能差异,突出说明了即使强大模型在上下文不足时也容易产生自信的错误。 III. RAG进阶:优化预上下文处理的高级技术 本章介绍了超越基础RAG、进一步优化预上下文处理流程的高级技术,并将其分为四个阶段: 1. 预检索优化:在索引前提升预生成数据的质量,如添加元数据、使用LLM提高信息密度、进行语义分块和假设性问题索引(HyDE)。 2. 精密检索策略:采用更智能的检索方法,如混合搜索(结合关键词与语义)、查询路由、分层检索和自查询检索。 3. 后检索优化:对检索到的上下文进行再处理,如重排序、上下文压缩/蒸馏,以及使用纠正性RAG(CRAG)进行质量评估与过滤。 4. 生成阶段优化:通过思维链提示、少样本提示等技术,引导LLM更好地利用优化后的预生成上下文进行生成。 本章通过一个表格总结了各阶段关键技术及其对代码生成(尤其是处理质量不均文档时)的益处。 IV. 上下文高效处理的预计算、缓存与字符优化 本章探讨了除RAG外,其他提升上下文处理效率的补充策略: 1. 上下文学习与预训练:通过提示中的示例(上下文学习)或在领域数据上微调,将知识预置到模型中。 2. 上下文缓存:介绍了Transformer中的KV缓存技术以加速生成,并指出了其内存消耗大以及压缩技术可能损害代码远程依赖的问题。同时介绍了更高级的上下文缓存服务(如Gemini上下文缓存),可重复使用预加载的上下文以降低成本。 3. 缓存增强生成:介绍了CAG作为RAG的替代方案,它一次性将所有静态知识库预加载到模型缓存中,消除了实时检索步骤,在特定场景下速度更快、架构更简单。 4. 字符优化:讨论了通过提示工程、响应流式传输、智能上下文剪枝等手段,优化字符使用以控制成本和提升效率。 V. 构建处理大型代码库的稳健AI系统架构:支持高效的预上下文生成与利用 本章从系统架构角度,探讨如何构建支持预上下文生成与利用的稳健系统: 1. 设计原则:包括模块化、可扩展的数据处理流程、持续学习与更新机制,以及平衡性能与成本。 2. 关键架构模式:重点介绍了Copilot模式,即如何将LLM与RAG、技能集成等组件结合,构建上下文感知的辅助编程应用。 3. 动态知识图谱:提出将知识图谱作为更丰富、结构化的预计算上下文形式,用于建模代码实体间的复杂关系,从而增强RAG的推理能力和可解释性。 4. 上下文窗口管理:讨论了如何通过缓存、自适应注意力机制和RAG本身,来优化对有限上下文窗口的利用。 VI. 标准RAG的替代与补充方案探索:进一步提升预上下文利用效率 本章视野更广,探讨了可替代或补充RAG的其他技术路线: 1. Transformer架构优化:研究如Latte、Fast Multipole Attention、AnchorCoder等新架构,旨在从根本上降低注意力机制的计算复杂度,使其能更高效地处理预生成上下文。本章通过一个表格对比了这些优化技术。 2. 知识蒸馏:将大型“教师”模型的知识迁移到小型“学生”模型,以创建更轻量、高效的领域专用代码模型。 3. 受控生成与增量生成:通过将编程语言语法等规则作为预设上下文,引导LLM输出符合语法、无错误的代码。 4. 战略性微调:比较了微调主LLM与微调RAG嵌入模型的不同策略,以及它们与RAG的适用场景。 5. 专业化RAG架构:介绍了针对不同数据类型的结构化RAG、API增强RAG和基于知识的RAG。 VII. 上下文代码理解与生成案例研究:预上下文生成的实践应用 本章通过三个实际案例,展示了预上下文生成理念的应用: 1. DeepWiki (Cognition Labs):商业工具,自动将GitHub代码库转换为交互式AI维基,其问答和深度研究功能依赖于对代码库的预先分析和索引。 2. Context7 (Upstash):专注于为AI编码助手提供高质量、版本化的预生成代码上下文库(通过llms.txt格式),旨在减少因API知识过时而产生的幻觉。 3. DeepWiki-Open:DeepWiki的开源实现,其架构明确包含RAG模块(rag.py)和数据预处理管道,依赖于预生成的代码嵌入和文档。 这三个案例共同验证了基于RAG的预上下文生成是解决代码库理解与生成效率问题的有效工程路径。 VIII. 综合解决方案:构建以预上下文为核心的高性能AI代码生成系统 本章是全报告的总结与集成,提出了构建高性能系统的综合建议: 1. 战略选择:强调没有单一最佳方案,应根据代码库的动态性、资源限制、精度要求等具体场景,在RAG、缓存(CAG)、微调和模型架构优化之间做出权衡或组合使用。 2. 最佳实践:给出了管理大型、异构代码库的具体操作建议,包括稳健的数据预处理、代码感知分块、丰富元数据提取、实施混合搜索与CRAG等质量过滤机制,以及建立定期的预生成上下文库更新流程。 3. 风险缓解:讨论了如何通过高质量的预生成上下文、上下文充分性评估、生成后验证、安全扫描集成以及严格的访问控制,来减轻幻觉、安全性和知识产权风险。 4. 未来展望:指出了知识图谱更深集成、自我改进系统(自适应RAG)、多模态上下文、专门化小型代码模型等前沿方向。 报告最后通过一个综合性对比表格,从效率、复杂性、可扩展性、成本等维度,系统比较了基础RAG、高级RAG、微调、知识蒸馏等多种技术的特性与适用场景。 总结而言,这份报告系统性地论证了“预上下文生成”作为解决生成式AI代码生成效率瓶颈的核心工程策略。它从问题分析、基础方法(RAG)、高级优化、架构设计、替代方案、实践案例到综合构建方案,提供了一个完整的知识框架,最终导向一个结论:未来的高性能AI代码生成系统,必然是集成了智能化上下文预生成、管理和高效检索能力的工程化、情境感知系统。
11分钟 ·40 - 通过分析关键因素理解RAG系统性能
这篇题为《通过分析关键因素理解RAG系统性能》的论文,由Shengming Zhao撰写,旨在系统性地研究检索增强生成(RAG)系统的性能行为。论文指出,尽管RAG系统能显著提升大语言模型(LLM)在知识密集型任务中的表现,但其复杂的设计空间(如检索器选择、查询优化、提示工程等)使得系统开发、维护和优化面临巨大挑战。 为此,作者提出了一个新颖的系统因素分析框架。该框架不直接评估无数设计决策的组合,而是将它们抽象为可观察的系统因素,作为分析与解释的中间层。论文重点研究了三个关键系统因素: 1. 检索召回率:研究发现,RAG系统要超越独立LLM所需的召回率阈值因模型和数据集差异巨大(20%到100%不等)。即使召回率达到100%,RAG系统仍可能在部分独立LLM能正确回答的问题上失败。 2. 检索文档类型:论文将文档按“是否包含有用信息”和“是否被检索器高度相似排名”分为三类:Oracle(有用)、Distracting(高相似但无用)、Irrelevant(低相似且无用)。研究发现,在代码生成任务中,无关文档有时甚至比有用文档表现更好,这是一个反直觉的发现。 3. 提示技术:研究评估了多种先进提示技术(如Few-shot、CoT、Self-Refine等),发现其效果高度依赖于具体任务和数据集,没有“ universally better”的技术。复杂的提示技术可能会解决一些简单提示无法处理的问题,但也会在另一些简单提示能解决的问题上失败。 此外,论文探索了使用困惑度作为低成本、实时代理指标来监控系统因素的可能性。结果表明,在问答任务中,困惑度与检索召回率显著负相关,并能有效区分文档质量;但在代码生成任务中,这种相关性不成立,揭示了领域特异性。 论文的主要贡献在于提供了一个系统性的分析框架,揭示了RAG系统性能与关键因素之间的复杂关系,并为开发者构建更可靠、高效的RAG系统提供了重要启示。 根据提供的PDF论文《Understanding RAG Systems Performance by Profiling Key Factors》,以下是各章节内容的详细介绍: 第1章:引言 本章介绍了研究背景、RAG系统的基本框架、面临的挑战以及本文的研究方法。 * 背景:大型语言模型(LLM)已成为强大工具,而检索增强生成(RAG)技术通过整合外部知识库,显著提升了LLM在知识密集型任务中的性能。 * 基本RAG框架:将RAG系统抽象为两个阶段:检索阶段(根据用户查询从索引数据库中检索相关文档)和生成阶段(将检索到的文档与原始查询组合成提示,输入给LLM生成最终答案)。 * RAG设计选择与高级技术:详细阐述了构建高效RAG系统涉及的众多设计决策,包括高级检索技术(如索引优化、查询优化、混合搜索、重排序、上下文摘要)和增强生成策略(如复杂的提示工程、迭代检索-生成方法)。 * RAG系统开发的挑战:设计复杂性与性能可变性:设计空间巨大且组合爆炸,使得穷举评估不切实际。 诊断与优化挑战:系统多组件架构导致故障点分散,且组件间存在复杂的相互依赖关系,使得定位根本原因和优化变得困难。 * 本文方法:为解决上述挑战,本文没有直接分析具体的设计选择,而是提出了一个系统因子分析框架。该框架聚焦于三个可观察的中间结果(系统因子)来分析RAG系统行为:检索召回率分析:研究成功检索到的相关信息比例如何影响系统性能。 检索文档类型分析:根据是否包含有用信息以及检索器给出的相似度评分,将文档分类为Oracle文档(包含有用信息)、干扰文档(高相似度但无有用信息)和无关文档(低相似度且无有用信息),并分析其影响。 提示技术分析:评估不同提示工程方法在RAG上下文中的效果。 此外,本文还探索使用困惑度作为轻量级代理指标,以实时监控这些系统因子的变化。 第2章:研究设计 本章详细说明了实验设置,包括使用的数据集、评估指标、检索配置和LLM设置。 * 数据集:使用了六个数据集,涵盖软件工程(SE)和自然语言处理(NLP)领域。SE领域(代码生成):CoNaLa, DS1000, Pandas-Numpy Eval (PNE)。 NLP领域(问答):Natural Questions (NQ), TriviaQA, HotpotQA。 * 评估指标:领域特定性能指标:代码生成任务使用Pass@1(评估代码功能正确性);问答任务使用准确率(评估答案正确性)。 系统监控代理指标:探索困惑度作为评估生成质量和模型置信度的指标。 * 检索设置:描述了为代码和问答数据集构建知识库语料、识别Oracle文档的方法,并选择OpenAI的text-embedding-3-small模型作为检索器。 * LLM设置:使用了两个代表性的LLM:开源的Llama 2-13B(代码任务使用CodeLlama变体)和闭源的GPT-3.5 Turbo。实验采用贪婪解码以确保可复现性。 第3章:检索召回率 本章通过控制实验,深入分析了检索召回率对RAG系统性能的影响。 * 实验设置:通过用干扰文档随机替换部分Oracle文档,模拟不同召回率水平(0%, 20%, 40%, 60%, 80%, 100%),同时保持文档数量和提示长度一致。 * 关键发现:性能随信息量提升,但有例外:在大多数情况下,召回率与系统正确率呈正相关。但在DS1000等复杂代码数据集上,由于问题复杂性高,这种关系存在波动。 召回率阈值悖论:RAG系统需要达到一个最低召回率阈值才能超越独立LLM的性能。该阈值因模型和数据集差异巨大(从20%到100%不等)。例如,对于基线性能已经很高的任务(如GPT-3.5在TriviaQA上),RAG需要近乎完美的召回才能带来增益。 完美检索悖论:即使召回率达到100%,RAG系统仍然会在部分独立LLM能够正确回答的问题上失败。这表明有效检索是必要的,但并非充分的,RAG系统本身可能存在性能退化问题。 * 困惑度作为检索召回率的代理指标:在问答任务中,困惑度与检索召回率呈现清晰的负相关关系(召回率越高,困惑度越低),统计检验显著,表明困惑度可作为有效的代理监控指标。 在代码生成任务中,这种关系不一致且统计上不显著,表明困惑度在此领域作为召回率代理的可靠性较低。 第4章:检索文档类型分析 本章系统研究了不同质量的检索文档对RAG系统的影响。 * 文档分类:基于“是否包含有用信息”和“是否被检索器评为高相似度”两个维度,将文档分为三类:Oracle文档、干扰文档、无关文档(进一步细分为随机、不同领域、虚拟无意义文本)。 * 关键发现:干扰文档的影响因任务域而异:在知识密集型的问答任务中,干扰文档和无关文档的性能影响相似(都缺乏有用信息)。但在代码生成任务中,干扰文档比无关文档造成的性能下降更严重,因为它们会“误导”LLM,干扰其内部推理能力。这表明对于代码任务,检索精度(避免误导性文档)比单纯追求高召回率更重要。 无关文档的反直觉优势:在代码生成任务中,仅使用无关文档的RAG系统,其性能有时能匹配甚至超过使用Oracle文档的系统。尤其是来自完全不同领域的“diff”文档,效果显著。进一步的实验表明,单纯增加无关文档(如“diff”或“dummy”)就能提升代码生成性能,这可能是一种特殊的提示条件作用,能激发LLM更好地利用其内部知识。 * 困惑度作为文档质量的指标:在问答任务中,Oracle文档对应更低的困惑度,符合预期。 在代码生成任务中,无关文档常常导致最低的困惑度,但这与实际的性能(Pass@1)并不匹配。这凸显了困惑度在评估代码生成任务时的局限性。 第5章:提示技术 本章评估了多种先进的提示技术在RAG系统中的效果。 * 实验设置:从四大类别(提示调优、思维生成、问题分解、内容验证)中选取了八种代表性技术(如Few-shot、Chain-of-Thought、Self-Refine、Chain-of-Note等),并精心设计提示进行测试。 * 关键发现:高级提示技术的益处有限且高度依赖上下文:没有一种提示技术能在所有数据集和模型上 consistently 超越简单的零样本提示。技术的有效性高度依赖于具体任务、数据集和使用的LLM。 性能增益与损失的权衡:虽然某些高级技术可以解决一些零样本提示无法解决的问题,但它们也可能在一些零样本提示能解决的问题上失败。这表明提示复杂度并非单纯提升能力,而是改变了模型可解决问题的分布。 困惑度与提示技术性能脱节:一些能提高性能的提示技术(如Few-shot)反而会产生更高的困惑度。这表明困惑度不能可靠地预测不同提示技术下的RAG系统性能。 第6章:讨论 本章总结了研究发现,并阐述了其对RAG系统设计、开发和优化的启示。 * 应对RAG系统性能退化:识别了由检索失败(如返回干扰文档)和生成失败(即使检索完美也无法有效利用信息)导致的退化模式。 * 系统因子的代理指标:困惑度在问答任务中可作为检索召回率和文档质量的有效代理指标,为实时、低成本监控提供了可能;但在代码任务中作用有限。 * 无关文档的效应:在代码生成中观察到的无关文档的正面作用,为优化提示设计提供了新思路。 * 代码任务的检索:强调在代码生成中,避免检索到高相似度的干扰文档比追求高召回率更重要。 * 多任务场景的提示优化:由于提示技术效果高度依赖上下文,为多任务场景寻找一个“通用最优提示”非常困难,需要针对性的优化。 第7章:相关工作 本章回顾了与RAG系统、LLM评估、软件工程中的代码生成以及提示工程相关的现有研究,并定位了本文工作的创新点——首次从系统集成和因子分析的 holistic 视角系统研究RAG。 第8章:局限性 本章坦诚地指出了研究的局限性,例如:使用的LLM和数据集范围有限;对“无关文档提升代码性能”等现象的机制探索尚不深入;代理指标困惑度的有效性在不同领域不均等。 第9章:结论 本章总结了全文的核心贡献: 1. 提出了一个新颖的“系统因子分析框架”,通过检索召回率、文档类型和提示技术这三个可观察因子来理解和诊断RAG系统,避免了穷举设计选择的复杂性。 2. 探索了困惑度作为轻量级代理指标的潜力与局限,为实时系统监控提供了工具。 3. 揭示了RAG系统一系列关键但反直觉的行为特征与权衡,如代码生成中无关文档的积极作用、检索召回率阈值的巨大变化、提示技术效果的强上下文依赖性等。 本文为理解和开发更可靠、高效的RAG系统提供了重要的理论基础和实践启示。
11分钟 ·10 - SolEval:面向仓库级 Solidity 代码生成的大语言模型评测基准
SolEval是第一个用于评估大语言模型(LLM)在仓库级别生成Solidity智能合约的基准测试: 1. 研究背景与动机 * 问题:LLM在代码生成方面取得了巨大进展,但现有基准(如HumanEval、MBPP)主要关注Python、Java等主流语言,严重缺乏对Solidity(以太坊主要智能合约语言)的评估。 * 挑战:Solidity开发受gas费用(执行成本)和区块链不可变性的约束,使得代码生成比通用编程语言更具挑战性。 * 现有工作的不足:此前唯一的Solidity基准BenchSol规模极小(仅15个用例),且仅评估独立函数生成,与需要处理跨文件依赖的真实世界仓库级开发场景脱节。 2. SolEval基准的构建 * 规模与来源:包含 1,125个样本,源自 9个真实世界的开源Solidity仓库,覆盖安全、金融、游戏等 6个流行领域。 * 关键特性:仓库级评估:重点关注非独立函数的生成,要求模型理解并利用来自其他文件的上下文依赖(如接口、变量、函数)。 人工标注:由5名有经验的硕士生对函数需求(注释)进行手动标注,以减少LLM的记忆效应并提供高质量描述。 全面评估指标:不仅评估功能正确性,还引入了对智能合约至关重要的质量属性:功能正确性:使用 Pass@k 和 Compile@k 指标。 Gas费用:衡量生成合约的执行成本。 漏洞率:使用Slither工具检测生成代码中的安全漏洞。 * 构建流程:包括项目筛选、函数解析、测试构建、人工标注和上下文解析五个阶段,确保数据的多样性、真实性和可评估性。 3. 实验评估与主要发现 对 10个主流LLM进行了评估,并探究了以下研究问题: * RQ1:整体性能如何?所有模型在Solidity代码生成上表现远未达到理想水平。性能最佳的DeepSeek-V3的 Pass@10 也仅为 26.29%,表明有巨大改进空间。 存在正确性与Gas效率的权衡:例如,DeepSeek-V3正确率最高但Gas费用也高;而DeepSeek-R1-Distill-Qwen-7B正确率最低但生成的合约最省Gas。 * RQ2:不同配置如何影响效果?RAG(检索增强生成)和上下文信息能有效提升模型的功能正确性(Pass@1 和 Compile@1)。 更大的模型不一定生成更省Gas的代码(例如,GPT-4o-mini在Gas优化上优于GPT-4o)。 提供过多的示例(few-shot)会导致输入长度和耗时大幅增加,但性能提升有限。 4. 贡献总结 1. 指出局限:明确了现有Solidity基准在规模和真实性方面的不足。 2. 提出新基准:发布了首个大规模、仓库级的Solidity智能合约生成基准SolEval,包含丰富的真实样本和关键的质量评估维度(Gas、漏洞)。 3. 全面评估:对10个SOTA LLM进行了广泛评估,揭示了它们在Solidity生成上的性能差距,并验证了RAG和上下文信息的有效性。 5. 未来工作与局限 * 未来方向:扩展更多仓库和测试用例;支持多语言(如Vyper、Rust)评估。 * 当前局限:仅支持Solidity单语言;因资源未评估某些最新模型;Gas和漏洞指标仅用于评估,未提供优化方法。 以下是每一章节的详细介绍: 摘要 (Abstract) * 核心内容:介绍了研究背景、问题陈述和主要贡献。 * 详细说明:指出大型语言模型(LLMs)在代码生成方面取得了变革性进展,但现有研究主要集中在Python、Java等主流语言,忽视了以太坊智能合约的主要语言Solidity。由于缺乏足够的Solidity基准测试,LLMs生成安全、经济高效的智能合约的能力尚未得到充分探索。为此,作者构建了SolEval,这是第一个为Solidity智能合约生成设计的仓库级(repository-level)基准测试。SolEval包含来自9个不同仓库的1125个样本,覆盖6个流行领域,并引入了燃气费(gas fee) 和漏洞率(vulnerability rate) 这两个关键现实属性。对10个LLMs的评估结果显示,表现最佳的模型Pass@10也仅为26.29%,表明LLMs在Solidity代码生成方面仍有巨大改进空间。 1. 引言 (Introduction) * 核心内容:阐述了研究动机、现有工作的局限性以及SolEval的必要性。 * 详细说明:随着区块链和去中心化金融(DeFi)的快速发展,智能合约部署激增,对高效可靠的Solidity代码生成工具需求迫切。LLMs已成为代码生成的主导方法,但现有基准测试(如HumanEval, MBPP, ClassEval)大多关注Python和Java。Solidity语言因其受燃气费和区块链不可变性的约束,代码生成更具挑战性。现有的Solidity基准测试BenchSol规模极小(仅15个用例),且由GPT-4生成,与真实场景脱节,仅支持独立函数评估。为了填补与现实世界对齐的Solidity基准测试空白,作者提出了SolEval,它是第一个支持仓库级智能合约生成的基准测试,包含非独立函数(依赖仓库上下文),并具有规模大、人工标注、包含关键质量属性(燃气费、漏洞率)等特点。 2. 基准测试 - SolEval (Benchmark - SolEval) * 核心内容:详细描述了SolEval基准测试的设计、输入输出和评估指标。 * 详细说明:2.1 概述 (Overview):SolEval包含1125个样本,来自9个真实代码仓库,覆盖6个领域。其设计用于评估LLMs在仓库级智能合约生成上的性能,包含两个关键阶段:(1) 基于LLM的Solidity代码生成 和 (2) 后生成评估。 2.2 基于LLM的Solidity代码生成 (LLM-based Solidity Code Generation):LLM接收的输入包括:① 函数签名、② 需求(自然语言描述)、③ & ④ 仓库上下文(被引用代码的接口、函数、变量等)。LLM根据这些输入生成目标函数。 2.3 后生成评估 (Post-Generation Evaluation):使用Forge工具执行测试用例进行评估。评估指标包括:功能正确性:Pass@k(至少有一个生成样本通过测试的比例)和 Compile@k(至少有一个生成样本编译成功的比例)。 质量属性:燃气费 (Gas Fee)(执行测试的燃气消耗,与原始函数对比)和 漏洞率 (Vul)(使用Slither静态分析工具检测出的高风险漏洞比例)。 3. 基准构建 (Benchmark Construction) * 核心内容:详细说明了SolEval数据集的构建流程,包括五个关键阶段。 * 详细说明:3.1 项目选择 (Project Selection):从OpenZeppelin等6个流行GitHub组织中筛选高质量、有测试用例的Solidity项目仓库。 3.2 函数解析 (Function Parsing):设计Solidity版本的Tree-sitter来解析合约,提取函数信息,并过滤掉测试函数、接口和过短的函数,最终得到1125个函数样本。 3.3 测试构建 (Test Construction):收集并确保每个函数有完整的单元测试覆盖(包括模糊测试、不变性测试等),并建立函数与测试用例的映射关系以提高评估效率。 3.4 人工标注 (Human Annotation):招募5名有至少3年Solidity经验的硕士生对函数需求进行人工标注,以减少LLM的“记忆效应”并提供高质量注释。使用Fleiss‘ Kappa评估标注者间的一致性,结果优秀。 3.5 上下文解析 (Context Parsing):通过静态程序分析识别每个函数所依赖的上下文(如外部调用的函数签名、变量等),这是SolEval与BenchSol的关键区别之一,有助于避免编译错误并验证模型对需求的理解。 4. 实验设置 (Experimental Setup) * 核心内容:介绍了评估所使用的大型语言模型、评估方法以及研究问题。 * 详细说明: 研究问题:RQ-1 整体正确性:LLMs在Solidity代码生成上表现如何? RQ-2 敏感性分析:不同配置如何影响LLMs的有效性? 4.1 研究的LLMs (Studied LLMs):选择了10个最先进的LLMs,包括闭源模型(如GPT-4o, GPT-4o-mini)和开源模型(如CodeLlama, DeepSeek-Coder),涵盖不同规模(6.7B到671B参数)和类型(通用LLM和代码专用LLM)。 4.2 评估方法与指标 (Evaluation Methodology and Metrics):采用Pass@k和提出的Compile@k作为主要指标(k=1,5,10)。同时评估燃气费和漏洞率。实验还使用了检索增强生成(RAG) 技术来选取最佳示例。所有实验结果均为5次独立运行的平均值。 5. 结果 (Results) * 核心内容:展示了实验结果并回答了研究问题。 * 详细说明: 5.1 RQ-1:LLMs在Solidity代码生成上表现如何?功能正确性:在评估的10个LLMs中,DeepSeek-V3 (671B) 表现最佳,Pass@10达到26.29%,但整体水平仍较低,表明LLMs生成正确的Solidity合约(尤其是非独立函数)非常困难。不同规模的模型内部比较显示,Qwen2.5-Coder在32B-34B模型中领先。 质量属性:不同LLM生成的合约在燃气费和漏洞率上差异显著。例如,DeepSeek-V3正确率最高,但生成的合约燃气效率较低;而GPT-4o-mini正确率低于GPT-4o,但生成的合约燃气费更低。这揭示了功能正确性与燃气效率之间的权衡困境。 5.2 RQ-2:不同配置如何影响LLMs的有效性?示例数量的影响:增加提示中的示例数量会显著增加平均令牌长度和运行时间,但对Pass@k的提升有限。因此,后续实验采用单样本(one-shot) 设置。 选择策略的影响:使用RAG检索相关示例比随机选择示例能带来更高的Pass@1和Compile@1,表明RAG能提升代码生成效果。 上下文信息的影响:为LLM提供函数所需的上下文信息能提高Pass@1和Compile@1,但对燃气费和漏洞率没有明显影响。 5.3 经验教训 (Empirical Lessons):RAG和上下文信息能提升LLMs在Solidity合约生成上的性能。 LLMs有时能在复杂需求上生成优秀合约,却可能在简单问题上失败。 更大的语言模型不一定能改善生成代码的燃气费。 6. 相关工作 (Related Work) * 核心内容:回顾了与本研究相关的两大领域工作。 * 详细说明:6.1 大型语言模型 (Large Language Model):概述了代码生成LLMs(如CodeLlama, Magicoder, DeepSeek-Coder)的发展,以及针对主流语言的提示工程优化技术(如思维链、自我调试)。 6.2 代码生成基准测试 (Code Generation Benchmark):总结了针对主流语言(如Python, Java)的基准测试(如HumanEval, MBPP, DS-1000, Concode),并指出它们对Solidity语言的忽视。同时指出,BenchSol是此前唯一的Solidity基准测试,但其在规模、真实世界对齐和任务类型(仅限独立函数)上存在严重局限。 7. 结论与未来工作 (Conclusion and Future Work) * 核心内容:总结了研究贡献,并提出了未来的研究方向。 * 详细说明:本文提出了SolEval,这是第一个用于评估LLMs在Solidity智能合约生成场景下有效性的仓库级基准测试。与BenchSol相比,SolEval在任务规模(75倍)、真实世界代码对齐以及关键属性评估(燃气费、漏洞率)方面具有显著优势。实验揭示了当前最先进LLMs在生成非独立Solidity函数方面的局限性。未来工作有两个方向:1) 从GitHub寻找更多高质量仓库,扩大数据集;2) 支持更多编程语言,使其成为多语言基准测试。
16分钟 ·10 - 量化RAG优势:基于LLM的代码生成多指标基准测试
这篇论文题为《量化RAG优势:基于LLM的代码生成多指标基准测试》,旨在评估检索增强生成(RAG)技术对大型语言模型(LLM)在解决编程问题(特别是LeetCode算法题)时性能的影响。以下是主要内容总结: 研究背景与问题 * LLM在代码生成任务中表现出色,但在面对复杂或不熟悉的算法问题时,常出现“幻觉”(生成无效或逻辑错误的代码)和性能下降。 * RAG通过从外部知识库检索相关信息来增强提示,有望弥补LLM的不足,但此前缺乏针对编程问题的系统评估。 方法论 1. 数据集:知识库:包含120个LeetCode问题,每个问题配有已验证的代码解决方案和自然语言解释。 测试集:30个未见过的LeetCode问题,用于评估泛化能力。 问题涵盖不同难度(Easy/Medium/Hard)和发布年份,以测试系统鲁棒性。 2. 信息检索(IR)系统:使用预训练模型(all-MiniLM-L6-v2)将问题描述转换为向量嵌入。 基于FAISS索引和余弦相似度检索相似问题,并采用动态阈值机制(初始阈值65%,根据最高相似度动态调整)来筛选相关上下文。 3. 模型选择:评估了六种LLM:GPT-4 omni、Claude 3.7 Sonnet、GPT-3.5 Turbo、Gemini 2.0 Flash、Qwen2.5-Coder-32B和DeepSeek-R1,涵盖通用型、代码专用型及不同能力水平的模型。 4. 实验设计:每个测试问题分别用“无RAG”和“有RAG”两种方式处理:RAG版本会检索知识库中最相似的已解决问题,并将其解决方案和解释作为上下文加入提示。 生成的代码通过LeetCode评测系统验证正确性,并记录运行时和内存使用效率(以“超越用户提交的百分比”衡量)。 主要结果 1. 正确性提升:多数模型在RAG增强后正确率提高,整体平均提升6.1%。 GPT-3.5 Turbo提升最显著(从50.0%到66.7%),表明RAG对能力较弱的模型帮助更大。 DeepSeek-R1达到最高正确率(96.7%),仅有一个错误。 Gemini 2.0和Qwen2.5-Coder正确率不变,但效率指标改善。 2. 效率改进:运行时效率:所有模型均有提升,中位数改善6.3%(如Qwen2.5-Coder从68.9%提升至81.3%)。 内存效率:平均提升11.0%,其中Gemini 2.0从40.1%提升至56.0%。 3. 按问题特性分析:难度:Easy问题正确率达100%;Medium和Hard问题也有改善。 发布时间:对2023年后发布的问题改善更明显(正确率从60.4%提升至70.8%)。 结论与未来工作 * RAG能有效提升LLM解决编程问题的正确性、速度和内存效率,尤其对能力较弱的模型或较新问题帮助更大。 * 局限性:仅使用LeetCode单一数据源;未排除“更长提示本身带来提升”的可能性。 * 未来方向:扩展至更多编程平台;增加随机检索基线对比;探索更大知识库的扩展性。 意义 * 为教育领域(如编程学习助手)和代码生成工具提供了改进思路。 * 首次将RAG系统应用于编程问题求解,并引入多维度(正确性、运行时、内存)评估基准。 该研究通过严谨的实验设计,证实了RAG在代码生成任务中的实用价值,并为后续研究提供了可复现的基准框架。 根据提供的文章《Quantifying the RAG Advantage: A Multi-Metric Benchmark for LLM-based Code Generation》,以下是各章节内容的详细介绍: 摘要 (Abstract) 本章概述了全文的核心。它指出,尽管大语言模型在代码生成方面表现出色,但仍存在幻觉问题,且在处理不熟悉或复杂任务时性能有限。检索增强生成通过为提示词补充相关外部信息,成为解决这些限制的有前景方案。本文提出了一个基准测试,通过整合一个包含120个LeetCode问题(每个问题都配有已验证的解决方案和解释)的精选数据库,来评估RAG在解决算法问题上的效能。使用了一个信息检索系统来为求解新问题构建增强提示。 1. 引言 (Introduction) 本章详细阐述了研究背景和动机。尽管LLMs在代码生成任务上能力突出,但在面对复杂算法问题时,经常产生错误或低效的解决方案,这通常源于特定上下文知识的缺乏和对底层数据结构的有限理解,从而导致幻觉。RAG被提出作为一种机制,通过信息检索算法从结构化语料库中检索上下文相似的信息,从而将模型的输出建立在相关外部知识之上。本研究的主要目标是评估RAG是否能提高LLMs解决编程问题的性能。为此,创建了一个包含120个LeetCode问题的数据库作为RAG系统的知识库,并使用基于余弦相似度和动态阈值的IR管道进行检索。在一个独立的、包含30个未见问题的测试集上进行评估,利用LeetCode评测系统验证解决方案的正确性和性能(运行时间和内存使用)。本章强调,这是首次将RAG应用于检索相似示例来解决编程问题的工作,并且评估超越了单纯正确性,还分析了运行效率和问题难度、发布年份的变化对系统鲁棒性的影响。 2. 相关工作 (Related Works) 本章回顾了相关领域的研究。首先总结了多项在没有RAG的情况下评估LLMs解决竞争性编程问题(如LeetCode)能力的研究,本文从这些研究的评估策略和模型选择中汲取了灵感。接着,特别提到了2024年SBBD上的一项类似研究,该研究将RAG应用于提升LLMs在巴西大学入学考试上的表现,其目标(减少幻觉、提高答案可靠性)与本文紧密相关。这些前期工作为本文的研究奠定了基础,例如,本文采纳了相关工作中使用运行时间和内存作为评估指标的建议,并受其按时间和难度划分问题的启发,将这些策略扩展到了RAG的语境中。 3. 方法论 (Methodology) 本章详细说明了实验设计。 * 3.1 信息检索算法:描述了IR系统的具体实现。使用 all-MiniLM-L6-v2 模型将问题描述转换为向量嵌入,并使用FAISS(IndexFlatL2)建立索引进行相似度搜索。关键特点是采用了自适应阈值机制:初始相似度阈值为65%,但会根据最高相似度得分动态调整(高于80%则收紧,低于70%则放宽,但不低于65%),旨在减少噪声。 * 3.2 数据集概述:介绍了知识库和测试集的构成。知识库包含120个LeetCode问题,每个条目包括标题、难度、分类、问题文本、已验证的优化代码解决方案和详细解释。测试集包含30个未见过的LeetCode问题,用于公平评估泛化能力。两个数据集的难度分布(简单、中等、困难)和算法类别都经过精心设计,以确保评估的全面性。文中提供了一个表格展示具体分布。 * 3.3 模型选择:说明了选用的六个LLMs:GPT-4o、Claude 3.7 Sonnet、GPT-3.5 Turbo、Gemini 2.0 Flash、Qwen2.5-Coder-32B 和 DeepSeek-R1。选择依据包括它们在先前研究中的使用情况、训练重点的多样性(如代码专用、高级推理、通用目的)以及知识截止日期的不同。 * 3.4 实验:描述了实验流程。每个测试问题都会提交给所有六个LLMs,分别在“无RAG”和“有RAG”两种条件下进行。在RAG条件下,IR系统会从知识库中检索相似问题,并将这些问题的完整信息(包括相似度得分、标题、分类、解决方案代码和解释)整合到最终提示词中。模型生成的代码由LeetCode评测系统验证正确性,并获取其在运行时间和内存使用上超越其他用户提交的百分比排名。 4. 结果与分析 (Results and Analysis) 本章展示了实验结果并进行了深入分析。 * 正确性:数据显示RAG提升了多数模型的正确性。六个模型中有四个在获得增强后正确率提高,其中GPT-3.5 Turbo提升最显著(从50.0%到66.7%)。总体正确率提升了6.1%。Gemini 2.0和Qwen2.5-Coder正确率保持不变,但效率指标有改善。DeepSeek-R1结合RAG取得了最高正确率(96.7%)。文中通过一个表格(图1)直观对比了各模型在有/无RAG时的正确率。 * 效率:RAG显著改善了代码的运算效率。所有模型在运行速度上都有提升,中位数提升6.3%;在内存效率上提升更明显,平均提升11.0%。文中通过另一个表格(图2)展示了各模型在有/无RAG时在速度和内存百分位数上的表现。 * 按问题特性分析:结果还按问题难度和发布年份进行了细分。RAG在简单问题上达到100%正确率,在中等和困难问题上也有提升。对于2023年之后发布的新问题,RAG带来的正确率提升更为明显(从60.4%到70.8%)。文中通过表格(表2)总结了这些跨类别的性能对比。 5. 结论与未来工作 (Conclusion and Future Work) 本章总结了研究发现并展望了后续研究方向。结论指出,本研究提供的证据表明RAG可以提升LLMs解决编程问题的性能,包括正确性、运行时间和内存效率。这对教育等领域具有应用意义。同时,指出了本研究的局限性:仅依赖LeetCode单一数据源可能影响结论的普适性;性能提升可能源于更长的提示词而非检索质量本身。为此,未来的工作方向包括:在更多样化的编程平台上进行评估;引入随机检索问题作为基线进行更严谨的比较;探索使用更大知识库来提升检索质量。
19分钟 ·40 - CSEPrompts:计算机科学入门级提示词评测基准
这篇论文的主要内容包括: 1. 研究背景与动机:论文指出,大型语言模型(LLMs)如GPT系列在代码生成和文本创作方面能力强大,已广泛应用于包括教育在内的多个领域。这给计算机科学(CS)教育带来了机遇(如智能辅导)和挑战(如学术不端)。为了系统评估LLMs在CS入门教育中的实际能力与潜在影响,作者开展了此项研究。 2. 核心贡献:CSEPrompts基准框架:论文的核心工作是提出了 CSEPrompts,一个专门用于评估LLMs在入门级计算机科学任务上表现的基准测试集。该框架包含 269个练习提示,具体分为:219个编程练习:来自5个主流编程学习网站(如CodingBat、HackerRank)和3所大学在慕课平台(edX、Coursera)上提供的6门入门CS课程。 50个多项选择题:来自乔治亚理工学院的CS课程。 每个编程练习都配有至少5个测试用例,以确保评估的可靠性。 3. 实验设计与评估:研究选取了8个先进的LLMs进行评测,包括通用模型(如GPT-3.5、Llama-2)和专用代码模型(如Code-Llama、WizardCoder)。评估任务分为代码生成(根据问题描述编写Python代码)和选择题回答。代码通过测试用例判断正确性,选择题则直接比对答案。 4. 主要研究结果与结论:通过实验,论文回答了四个研究问题(RQs),得出以下关键结论:RQ1:所有测试模型都能产出较高质量的代码,其中GPT-3.5在各项任务上综合表现最佳。与现有通用代码基准(如HumanEval)相比,LLMs在CSEPrompts的学术课程题目上表现更差,说明其难度更高。 RQ2:来自编程网站的题目比学术慕课中的题目更容易被LLMs解决,表明学术题目通常更具挑战性。 RQ3:出乎意料的是,所测试的LLMs在代码生成任务上的表现优于选择题回答任务。 RQ4:专用代码模型在代码生成任务上通常优于通用模型,而通用模型在选择题回答上表现更好。 5. 未来工作:作者计划扩展CSEPrompts的数据集规模,并纳入更多LLMs进行更全面的评估。 总结:该论文通过构建一个贴近真实教育场景的基准测试集CSEPrompts,系统评估了多种LLMs在CS入门级编程和知识问答上的能力,揭示了它们在不同任务和题目来源上的性能差异,为理解LLMs对CS教育的影响提供了实证依据。 根据提供的文章《CSEPrompts: A Benchmark of Introductory Computer Science Prompts》,以下是每一章节的详细内容介绍: 1. 摘要 本章节概述了研究的背景、目的和主要贡献。随着大型语言模型(LLM)的进步,它们在学术和专业文本生成,特别是编程代码生成方面的能力日益增强,对计算机科学(CS)教育产生了显著影响。为了评估公开可用的LLM在CS入门教育中的潜在影响,研究者引入了 CSEPrompts——一个包含从入门CS和编程课程中收集的数百个编程练习提示和多项选择题的基准测试框架。文章还提供了在该基准上评估多个LLM生成Python代码和回答基础计算机科学及编程问题性能的实验结果。 2. 引言 本章节详细阐述了研究背景。首先回顾了NLP模型到LLM(如GPT-3、GPT-4)的发展,及其在医疗、教育等领域的革命性应用。重点讨论了LLM对教育,尤其是CS教育带来的机遇(如智能辅导系统)和挑战(如学生可能滥用其完成作业)。尽管已有研究关注GPT模型在教育评估中的表现,但本研究旨在进行更全面的评估,不局限于GPT系列模型。为此,文章提出了四个具体的研究问题,涉及LLM在入门CS作业上的表现、不同来源作业的难度差异、LLM在代码生成与选择题答题上的能力比较,以及专用代码LLM与通用LLM的性能差异。 3. 相关工作 本章节回顾了与代码生成和评估相关的先前工作。在生成式预训练模型兴起之前,代码任务多由CodeBERT等编码器模型处理,但在代码生成任务上表现一般。随着基于编码器-解码器或仅解码器架构的生成模型出现,代码生成能力得到提升,催生了如HumanEval、MBPP等统一基准测试数据集。然而,这些数据集主要关注软件开发中的常见任务,而非教育领域侧重于编程语言语法和语义核心理解的练习。CSEPrompts 的引入正是为了弥补这一空白,专注于从真实教育场景中收集的编程题目。 4. CSEPrompts框架 本章节详细介绍了 CSEPrompts 基准测试的构成和数据收集方法。 * 数据来源:框架包含269个练习提示,分为两部分:编程网站:从CodingBat、LearnPython、Edabit、Python Principles、HackerRank这五个流行的在线Python学习平台手动收集了118个编程提示。 学术慕课:从哈佛大学、密歇根大学、佐治亚理工学院在edX和Coursera平台上提供的六门入门Python课程中,收集了101个编程提示和50个多项选择题。 * 数据特点:每个编程提示都配有至少5个测试用例(多数基准为3个)。多项选择题包含5-10个选项。文章提供了关于提示长度(词元数)的详细统计数据,显示学术慕课的提示通常更长、更复杂。 * 收集策略:强调手动收集以确保数据质量并避免重复,旨在捕捉真实教育场景中的细微差别,这与HumanEval等人工专门编写的基准不同。 5. 实验 本章节描述了评估LLM性能的实验设置。 * 模型选择:评估了八种能够生成英文文本和Python代码的LLM,包括通用基础模型(如GPT-3.5、Llama-2、Falcon、MPT、Mistral)和专用代码微调模型(如Code-Llama、StarCoder、WizardCoder)。 * 评估任务与方法:代码生成:按照固定格式提示模型(如图1所示),模型生成响应后,手动提取代码片段,并使用pytest框架运行所有测试用例进行验证。 选择题答题:同样使用固定格式提示模型(如图2所示),要求其从给定选项中选择正确答案。 6. 结果 本章节展示了实验结果并进行了分析。 * 代码生成性能比较:将LLM在CSEPrompts编程任务上的表现(Pass@1指标)与现有基准HumanEval和MBPP进行了对比。结果显示,所有模型在CSEPrompts[慕课]子集上表现更好,而在CSEPrompts[学术]子集上表现更差。整体上,GPT-3.5表现最佳。 * 选择题答题性能比较:由于缺乏直接可比基准,选择了MathQA-Python进行对比。结果显示,对于大多数模型,回答选择题比回答MathQA中的开放式问题更容易,可能因为选择题选项提供了上下文引导。 * 针对研究问题的发现:RQ1:LLM在CSEPrompts上能产生高质量输出,GPT表现最优。与现有基准比,在慕课题目上更好,在学术题目上更差。 RQ2:来自编程网站的题目对大多数LLM来说比来自学术慕课的题目更容易,说明后者更具挑战性。 RQ3:尽管LLM主要为文本生成设计,但评估的模型在代码生成任务上的表现优于选择题答题任务。 RQ4:GPT-3.5作为通用模型在所有任务上领先。但总体趋势是,通用LLM在选择题上表现更好,而专用代码LLM在代码生成任务上表现更好。 7. 结论与未来工作 本章节总结了研究,并重申了对四个研究问题的回答(与结果部分一致)。主要结论包括:LLM在入门CS作业上表现出色且存在滥用风险;学术慕课的编程题目比编程网站的题目更难;当前评估的LLM更擅长生成代码而非回答选择题;专用代码LLM在代码生成上有优势,但最强的通用模型(GPT-3.5)综合表现最佳。未来工作方向包括扩展基准中的题目数量和模型种类,进行更全面的研究。
8分钟 ·20 - CODERAG-BENCH:检索增强能否有效提升代码生成效果?
这篇论文提出了 CODERAG-BENCH,一个用于系统评估检索增强代码生成 的综合性基准测试。其主要内容可总结如下: 1. 核心问题与动机 * 问题:尽管大语言模型在代码生成方面表现出色,但仅依赖其参数化知识难以生成许多复杂程序(如使用不熟悉的库或处理私有代码库)。虽然检索增强生成在文本任务中很成功,但其在代码生成中的应用潜力尚未被充分探索。 * 目标:创建一个统一的基准,以促进对代码导向RAG方法的研究、分析和改进。 2. CODERAG-BENCH 的构成 该基准是一个全栈式测试平台,包含: * 多样化的编程任务:涵盖四大类六种任务:基础编程:如HumanEval、MBPP,测试算法和内置函数。 开放域编码:如DS-1000、ODEX,需要调用外部库(如pandas, requests)。 仓库级问题:如RepoEval、SWE-bench,需要在完整代码仓库上下文中进行编辑。 代码检索:如CodeSearchNet,直接评估检索质量。 * 大规模的检索数据库:汇集了五种开发者常用资源,共约2500万文档:编程问题解决方案、在线教程、Python库官方文档、StackOverflow帖子、GitHub仓库文件。 * 高质量的标注:为大多数任务手动标注了规范文档(即解决问题所需的关键上下文),用于评估检索质量和RACG性能上限。 * 可复现的评估流程:提供统一的接口,用于检索、增强生成和执行评估(使用pass@k等指标)。 3. 主要实验与发现 论文进行了大规模评估(10种检索器,10种生成模型),关键发现包括: * 检索能显著提升代码生成:当提供高质量的规范文档时,生成模型(尤其是较弱模型)的性能大幅提升。例如,GPT-4o在SWE-Bench上获得了27.4%的增益。 * 当前RACG系统的两大瓶颈:检索器难以找到有用文档:特别是在开放域和仓库级任务上,检索质量(NDCG@10)普遍较低。 生成模型利用上下文的能力有限:模型容易被不相关文档干扰,或无法有效整合多个文档的信息。上下文窗口较小的模型改进幅度也较小。 * 不同任务的最佳检索来源不同:基础编程:StackOverflow帖子和教程最有帮助。 开放域:对于不常见的库,库文档和编程解决方案能带来最大增益。 仓库级:本地仓库内的代码片段至关重要,外部资源帮助有限。 * 检索模型对比:针对代码训练的密集检索模型(如Jina-v2-code)通常优于通用文本检索模型。 更大的检索模型(如SFR-Mistral)性能更好,但计算和存储成本也显著增加。 * 分块策略的影响:将文档预先分块为200-800个令牌的片段进行检索,通常比检索全文或检索后截断效果更好。 4. 结论与意义 * 结论:检索增强确实有潜力解决代码生成中知识不足的问题,但当前系统在检索和生成两端都存在明显限制,导致RACG结果尚未达到最优。 * 贡献:CODERAG-BENCH为未来研究提供了一个坚实的、可复现的测试平台,旨在推动更强大的代码检索器、能更好利用上下文的生成模型以及更先进的RACG方法的发展。 总之,这篇论文系统地论证了检索增强对于代码生成的价值与挑战,并发布了一个资源丰富的基准来引导该领域的未来研究。 根据提供的文章《CODERAG-BENCH: Can Retrieval Augment Code Generation?》,以下是各章节内容的详细介绍: 摘要 本文介绍了CODERAG-BENCH,一个用于评估检索增强代码生成 的综合性基准测试。尽管语言模型擅长生成代码,但许多程序仅靠模型内部知识难以生成。虽然检索增强生成在文本任务中很成功,但其在代码生成中的潜力尚未被充分探索。为此,本文创建了一个涵盖基础编程、开放域和仓库级问题等多种任务的基准,并提供了一个包含竞赛解决方案、教程、库文档、StackOverflow帖子和GitHub仓库的多样化、开放的代码检索数据库。基于此基准,作者对10个检索器和10个语言模型进行了大规模评估,系统分析了检索何时能有益于代码生成,并指出了剩余的挑战。研究发现,虽然检索高质量上下文能改进代码生成,但检索器常常难以获取有用的上下文,而生成器在有效利用这些上下文方面也存在局限。作者希望CODERAG-BENCH能推动面向代码的RAG方法的进一步发展。 1. 引言 随着语言模型的发展,从自然语言生成代码的能力迅速提升。然而,大多数模型遵循“自然语言到代码”的范式,没有集成外部上下文,这在诸如使用不熟悉的库等复杂场景中至关重要。仅依赖参数化知识也限制了模型在测试时适应新数据分布的能力。检索增强生成通过在推理时检索相关文档来解决这个问题,减少了对模型参数的依赖,并在各种任务中提高了准确性。尽管在基于文本的任务中取得了成功,但其在多样化编码问题和检索源中的应用仍未得到充分探索。本文提出了CODERAG-BENCH,一个旨在推进检索增强代码生成研究的整体性基准。 2. CODERAG-BENCH 本章详细介绍了基准的构建过程,其设计基于三个因素:任务多样性、严谨评估和统一接口。 * 2.1 编程问题:将现有的Python编码数据集分类并整合为四类:基础编程问题、开放域问题、仓库级问题和代码检索问题。每个类别都选取了多个广泛使用的数据集以确保多样性。 * 2.2 检索来源:从开发者常用的五种资源中收集检索文档:编程解决方案、在线教程、库文档、StackOverflow帖子和GitHub文件。基准支持两种检索设置:从规范数据存储中检索,以及从任何数据存储中进行开放检索。 * 2.3 规范文档标注:为确保可靠的检索评估并估计理想检索器下RACG系统的性能上限,为大多数示例手动标注了规范文档——即包含解决编程问题所需必要上下文的文档。 * 2.4 评估指标:对于检索,主要使用NDCG@10进行评估;对于代码生成,使用pass@k指标来衡量程序的执行正确性。 3. 规范RACG评估 本章使用规范数据源对CODERAG-BENCH进行了全面评估,包括文档检索、直接代码生成以及端到端的检索增强生成。 * 3.1 实验设置:采用了10个顶级检索模型和10个生成模型。检索模型涵盖稀疏、稠密和专有API三类;生成模型包括代码专用模型和强大的通用文本模型。 * 3.2 检索结果:分析了不同检索器在各类任务上的表现。发现稠密嵌入模型经常超越传统的BM25基线;专门针对代码检索训练的模型在相似参数量下通常表现更好;更大的检索模型往往带来更好的性能,但也伴随着显著的效率成本。 * 3.3 使用规范文档的生成:评估了模型在不使用检索和使用真实规范文档两种情况下的生成能力。结果显示,提供规范上下文在大多数情况下都能提升性能,尤其是在基础编程问题上。对于使用不常见库的挑战性任务,检索的效果更为明显。 * 3.4 检索增强代码生成:在完整的RACG设置下进行了实验。结果表明,最佳检索模型因任务和底层语言模型而异。在某些情况下,性能最好的检索模型并未带来最佳的RACG结果,这凸显了需要针对多样化任务整体评估RACG系统。 4. 开放检索下的RACG 除了从规范源检索,本章还探索了从所有可用来源进行开放检索的效果,并研究了最佳分块策略。 * 在基础编程问题上,StackOverflow帖子和教程能带来改进,混合多个来源的文档甚至能达到与使用真实文档相当的效果。 * 在开放域问题上,编程解决方案是最有帮助的来源。 * 在仓库级问题上,外部开放资源不如本地仓库中的代码片段有用,理解本地代码上下文至关重要。 * 在分块策略上,研究发现将文档分块到200-800个令牌通常能获得最佳结果,而检索前分块的策略在几乎所有文档源上都取得了最高分。 5. 相关工作 本章回顾了与本研究相关的两个领域: * 代码生成:神经代码生成已成为一个关键任务,出现了越来越多强大的代码语言模型。然而,大多数模型仅基于自然语言查询和参数知识生成代码,未利用外部编程资源。 * 检索增强生成:RAG已广泛应用于知识密集型任务,但主要集中于使用通用领域语料库的文本中心任务。一些工作使用了从仓库或文档中检索的编程上下文,但尚未有工作考虑跨多样化编码任务和知识源的RACG。 6. 结论 本文提出了CODERAG-BENCH,一个包含各种编码任务和检索源的检索增强代码生成基准。通过对顶级检索和生成模型的实验表明,检索外部文档可以极大地有益于代码生成。然而,当前的检索模型难以找到有用的文档,生成模型的上下文容量和RAG能力也有限,这两者都导致了次优的RACG结果。作者希望CODERAG-BENCH能作为一个坚实的测试平台,推动该领域的未来发展。 局限性:讨论了当前工作在任务和语言多样性、以及模型和方法改进方面的局限性。
8分钟 ·30