
 1
1 0
0根据提供的文章内容,这篇题为《大语言模型检索增强生成优化技术研究综述》的论文主要内容和结构总结如下:
1. 论文基本信息
- 标题:大语言模型检索增强生成优化技术研究综述
- 作者:袁乐、刘绍华、王禹、朱尚威、王焘、毛天露
- 发表期刊:计算机学报
- 网络首发日期:2025-11-20
2. 研究背景与动机
- 大语言模型(LLM)的局限:尽管LLM(如GPT、Llama系列)在自然语言处理领域表现出色,但仍面临“幻觉”、知识过时、推理过程不透明且难以追溯等挑战,限制了其在实际应用中的可靠性。
- RAG技术的引入:检索增强生成(RAG)通过整合外部数据库的实时信息,有效提升了模型的准确性、可信度和可解释性,成为解决上述问题的关键技术。
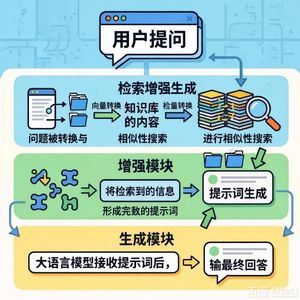
3. RAG核心框架
论文将RAG的工作流程划分为三个核心环节:
- 索引创建:包括数据准备(清洗、分块)、向量化表示和索引创建(存储键值对)。
- 检索:将用户查询向量化,计算与索引块的相似度,选择最相关的信息块。
- 生成:构建包含查询和检索内容的提示,利用LLM生成精确响应,并进行质量控制。
4. 增强优化技术体系(核心贡献)
论文以RAG工作流程为主线,提出了一个包含六个关键环节的增强优化框架:
(1) 预检索增强
旨在优化输入质量,提升检索意图清晰度。
- 输入增强:通过元数据提取(如NER)和语义提取精炼输入内容。
- 查询增强:通过查询重写(如RaFe、RQ-RAG)、语义扩展(如回译)和主题过滤与迭代,优化查询表达。
(2) 检索器增强
旨在提升检索精度及其与LLM的适配性。
- 检索器类型:对比了稀疏检索(BM25,高效但语义弱)、密集检索(DPR,语义强但资源消耗大)和生成式检索(GR,灵活但训练成本高)。
- 检索器与LLM对齐:包括微调检索器(如AAR)、引入适配器(如PRCA)和偏好对齐(如DPA-RAG),以弥合检索内容与生成需求间的差距。
(3) 检索策略增强
旨在提升检索过程的灵活性与深度。
- 多步优化策略:包括迭代检索(闭环反馈优化)和递归检索(层次化聚焦),适用于复杂推理任务。
- 动态调整策略:基于置信度判断、生成内容评估或任务复杂度动态触发检索,平衡效率与效果。
- 上下文增强策略:通过混合检索(融合关键词与语义)和上下文扩展(利用会话历史),提供更全面的背景信息。
(4) 索引增强
旨在提升数据质量与检索效率。
- 数据源增强:提升数据质量(如时效性处理)和优化数据结构(处理非结构化与结构化数据,如Graph RAG)。
- 索引结构优化:涉及分布式索引和层次化索引(如RAPTOR),以优化长文本处理。
(注:文章内容在第3.4节后截断,未完整展示“检索后增强”和“LLM增强”的具体细节,但摘要中提及了该框架包含这两个部分。)
5. 其他研究内容(基于摘要及引言)
- 对比分析:对比了检索增强与LLM增强的不同方法,分析了其适用场景。
- 资源总结:总结了RAG领域的主流数据集、基准任务和评估指标。
- 局限与展望:探讨了RAG技术的必要性、局限性(如检索质量、生成一致性、计算效率等),并展望了未来方向,包括动态多跳检索、长上下文管理、多模态RAG等。
6. 论文价值
该综述从优化视角出发,构建了系统化的RAG技术框架,不仅梳理了技术脉络,还深入剖析了各环节的理论依据与实现细节,为研究者和开发者提供了理论洞察与实践参考。
根据提供的文章《大语言模型检索增强生成优化技术研究综述》,其主要章节内容如下:
第1章 引言
本章回顾了检索增强生成(RAG)技术的发展脉络与研究现状。文章指出,尽管大语言模型(LLM)生成能力出色,但仍面临幻觉、知识过时和推理不透明等挑战。RAG技术通过整合外部数据库的实时信息,成为提升模型准确性和可信度的有效解决方案。本章还梳理了RAG从开放域问答兴起到当前LLM时代的发展历程,并明确了本文从优化视角出发、以工作流程为主线进行系统性综述的特色。
第2章 检索增强生成框架
本章勾勒了RAG工作流程的顶层设计,将其核心分解为三个环节:
- 索引创建:包括数据准备、向量化表示和创建索引,旨在高效组织数据以便检索。
- 检索:将用户查询转化为向量,在索引中计算相似度并选择最相关的信息块。
- 生成:将用户查询和检索到的信息块综合成提示,利用LLM生成响应,并关注生成质量控制。
第3章 增强优化环节
本章是全文核心,以RAG工作流程为主线,系统梳理了六个关键环节的增强优化策略:
- 预检索增强:优化输入查询,包括输入增强(提取关键信息)和查询增强(重写、扩展查询)。
- 检索器增强:优化检索器本身及其与LLM的对齐,包括稀疏、密集、生成式检索器及微调、适配器引入、偏好对齐等策略。
- 检索策略增强:优化检索逻辑,包括多步优化(迭代、递归检索)、动态调整(基于置信度、生成内容、任务复杂度触发检索)和上下文增强(混合检索、上下文扩展)策略。
- 索引增强:优化数据源和索引结构,包括提升数据质量、优化非结构化/结构化数据组织,以及采用分布式、分层索引提升效率。
- 检索后增强:对检索结果进行后处理,包括重排序与过滤(基于规则或模型)、信息压缩,以提升输入LLM内容的质量。
- 大语言模型增强:从模型自身能力出发进行优化,包括预训练增强(融入检索机制)、微调增强(任务特定调整)和推理增强(提示工程、智能体RAG)。
第4章 增强环节对比分析
本章将第3章的技术归纳为“检索增强”和“LLM增强”两大类,并进行对比分析。通过对比两者的技术路径、作用机制、优势局限及适用场景,揭示了它们“以外补内”和“以内强内”的不同优化哲学,并阐述了二者在知识广度与推理深度上的互补性,为系统优化提供指导。
第5章 数据集与评估指标
本章系统总结了RAG领域常用的数据集和评估指标。数据集涵盖特定领域问答、开放领域问答、结构化数据问答、推理问答、事实验证、长篇问答、低资源任务及对话式搜索问答等八大类别。评估指标则包括分类正确性、检索与生成平衡、生成质量、检索排序、证据支持及文档覆盖等多个维度,为模型训练与评估提供参考。
第6章 讨论
本章深入探讨了两个关键问题:
- RAG与上下文窗口扩展的关系:分析了长上下文窗口LLM的进展及其仍存在的中间遗忘、计算成本高等局限,论证了RAG在提升有效信息密度、灵活性、成本效益及实时更新能力方面的不可替代性,指出二者是互补而非替代关系。
- RAG的局限性:系统阐述了当前RAG技术在检索模块(召回不全、精度不足)、生成质量(与证据矛盾、一致性差)、长期记忆与上下文管理、计算成本与效率、可解释性与可控性、跨模态对齐以及长上下文中间遗忘等方面面临的挑战。
第7章 总结与展望
本章总结了全文,重申了本文以流程化视角系统剖析RAG优化技术的贡献。在此基础上,展望了未来六个重点研究方向:多跳与主动检索、长期记忆与上下文管理、降低幻觉与提升一致性、效率优化与可扩展性、结构化知识融合以及多模态RAG,旨在推动RAG技术在智能化、实用化方向上的进一步发展。
