
 3
3 0
0这篇论文题为《检索增强生成(RAG)综述:方法与应用》,由王鑫林、李岩、马超凡、李硕撰写,发表于《计算机科学》。文章针对大语言模型(LLM)存在的幻觉问题及知识滞后性,系统综述了检索增强生成(RAG)技术的方法、应用及未来方向。
以下是论文内容的详细总结:
1. 研究背景与动机
大语言模型在自然语言处理任务中表现出色,但受限于训练数据的封闭性与更新滞后,常生成偏离事实的内容(即“幻觉”)。RAG技术通过集成外部知识库,扩展了LLM的知识范围,有效提升了生成答案的准确性和可靠性。
2. RAG方法分类(核心贡献)
文章创新性地以“解决核心挑战”为主线,将现有的RAG方法划分为四大类别:
- 分块优化的RAG方法:挑战:传统分块策略(如固定长度、句子分块)易导致语义割裂或上下文丢失。
方法:包括“无需分块”方法(如CFIC、LE,直接对整体上下文建模)和“动态分块”方法(如MoG、LumberChunker、VGC,根据语义变化或视觉特征自适应调整分块粒度)。
优势:更好地保持语义完整性和上下文连贯性。 - 检索端改进的RAG方法:挑战:传统检索(稀疏/稠密)在复杂查询下易出现偏差,且检索内容可能对生成任务无实际帮助。
方法:包括迭代检索(如InteR)、主动多次检索(如FLARE)、自适应策略(如Adaptive-RAG)、自我反思机制(如Self-RAG)以及检索算法改进(如SIMLM)。
优势:实现检索与生成的深度协同,动态优化检索内容。 - 减少上下文输入的RAG方法:挑战:检索返回的大量文档导致上下文过长,增加计算成本并引入噪声。
方法:通过压缩与过滤技术,如模态融合(xRAG)、多智能体过滤(MAIN-RAG)、信息瓶颈理论(IB-RAG)、提示压缩(LLMLingua)及细粒度过滤(FILCO)。
优势:在保留关键信息的同时降低计算负担和推理延时。 - 与知识图谱结合的RAG方法:挑战:非结构化知识库存在质量参差不齐、结构缺失的问题。
方法:将知识转化为结构化图谱,利用图结构进行检索与推理。代表工作包括KAG(双向增强)、KGR(修正框架)、GraphReader(图代理系统)等。
优势:在多跳推理、实体消歧等复杂任务中表现卓越。
3. 评估与开源项目
- 基准与数据集:介绍了BEIR、MS MARCO、HotpotQA等用于评估检索、推理和生成能力的基准。
- 评价指标:涵盖了精确匹配(EM)、准确率、F1分数、MRR、NDCG、BLEU等指标。
- 开源项目:列举了AnythingLLM、RAGFlow、Dify、FastGPT、Langchain-Chatchat、Microsoft GraphRAG等主流框架,分析了其特点与适用场景。
4. 应用场景
- 下游任务:推荐系统(解决冷启动、长尾推荐)、软件工程(代码生成、文本转SQL)。
- 垂直领域:生物领域(药物发现、分子生成)、金融领域(股票预测、报告分析)。
5. 未来研究方向
- 多模态RAG:整合文本、图像、音频、视频等多模态信息,实现跨模态检索与生成(如MuRAG、mRAG)。
- RAG与Agent集成:结合智能体的自主决策、规划与反思能力,突破传统RAG线性工作流的限制,处理更复杂的任务(如MAD、RECONCILE框架)。
总结
该综述为研究人员提供了清晰的技术脉络,不仅系统梳理了RAG的技术演进,还通过对比分析指出了各类方法的适用场景(如分块优化适合长文档理解,知识图谱融合适合多跳推理),并对未来的多模态融合与智能化发展进行了展望。
根据提供的文章《检索增强生成(RAG)综述:方法与应用》,各章节主要内容如下:
1. 引言
- 核心问题:指出大语言模型(LLM)因训练数据封闭和更新滞后,在面对动态信息或专业领域知识时容易产生“幻觉”(生成不准确信息)。
- 解决方案:引入检索增强生成(RAG)技术,通过集成外部知识库来扩展LLM的知识范围,提升生成答案的准确性和质量。
- 文章创新点:区别于传统按流程划分的方式,本文以“解决核心挑战”为主线对RAG方法进行分类。
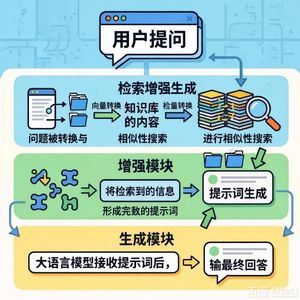
- RAG流程与挑战:概述了RAG索引、检索、生成三个关键步骤及其协同关系,并指出了实际应用中的四大核心挑战:知识库质量与结构问题、内容分块策略设计、检索策略优化、上下文长度过长。
2. RAG方法概述
- 分类框架:将现有的模块化RAG方法系统性地归纳为四大类别,以应对第1章提出的核心挑战。分块优化的RAG方法:核心是改进文本分块策略,以更好地保持语义完整性。分为“无需分块”(如CFIC、LE)和“动态分块”(如MoG、LumberChunker、VGC)两类。
检索端改进的RAG方法:旨在优化检索过程,使其更主动、适配。包括改进检索算法(如SIMLM)、迭代/自适应检索(如FLARE、Adaptive-RAG、Self-RAG)以及协同训练检索器与LLM(如ARL2、BGM)等方法。
减少上下文输入的RAG方法:核心是在生成阶段对检索到的长文档进行压缩或过滤,以降低计算负担、减少噪声干扰。方法包括信息压缩(如xRAG、LLMLingua)、信息过滤(如FILCO、MAIN-RAG)以及概念蒸馏(如AMR-RAG)等。
与知识图谱结合的RAG方法:利用结构化的知识图谱替代非结构化文本作为检索源,以提升复杂推理任务的准确性。涉及知识图谱构建(如iText2KG)、基于图谱的检索与推理(如GraphReader、SGP、AMAR)等。 - 对比分析:通过表格从准确性提升、计算成本、推理延迟、部署复杂度和适合任务类型等维度,对上述四类方法进行了对比总结。
3. RAG评估与开源项目
- 基准和数据集:列举了用于评估RAG系统检索、推理和生成能力的常用基准(如BEIR、HotpotQA)和涵盖问答、对话、摘要等多种任务的数据集。
- 评价指标:详细介绍了用于衡量RAG性能的多种指标,包括用于检索评估的精确率、召回率、F1分数、MRR、NDCG,以及用于生成评估的BLEU、METEOR等。
- 开源项目:介绍了8种主流的RAG开源框架(如AnythingLLM、RAGFlow、Dify、Microsoft GraphRAG),并说明了各自的特点和适用场景。
4. RAG应用
- 下游任务:介绍了RAG在通用任务场景中的应用,例如:推荐系统:通过整合外部知识(如评论)来改善冷启动、长尾推荐等问题(如RaRS、RevCore框架)。
软件工程:辅助代码生成、程序修复、文本到SQL解析等任务(如REDCODER、DocPrompting框架)。 - 垂直领域:介绍了RAG在高度专业化领域的应用,强调其对领域知识的精确调用能力:生物领域:应用于药物发现、分子设计等(如MolReGPT、RetMol框架)。
金融领域:用于整合实时市场数据、研究报告,提升股票预测、金融问答的准确性(如Stock-Chain框架)。
5. RAG未来方向
- 多模态RAG:指出RAG正从文本扩展到图像、音频、视频等多模态领域。通过统一表示学习、跨模态检索与生成(如MuRAG、mRAG框架),能在医疗、教育等场景提供更丰富的上下文理解。
- RAG与Agent集成:探讨将RAG与具备自主感知、规划和协作能力的智能体(Agent)相结合。这种集成能突破传统RAG静态工作流的限制,通过多智能体辩论、分层协调等模式(如MAD、Agentic RAG框架),在复杂任务中实现动态决策和迭代优化。
6. 结论
- 总结全文,重申RAG通过整合外部知识有效缓解了LLM在知识密集型任务中的幻觉问题。
- 概括了本文以解决核心挑战为主线,从四个维度对RAG前沿技术进行的梳理与剖析,旨在为研究人员提供清晰的技术脉络和选型参考。
- 指出本文受视角所限,未对知识源可靠性等根本性问题展开深入探讨,并承认这是RAG系统稳健性面临的关键挑战之一。
