
 5
5 0
0本文系统性地回顾和总结了2021年至2024年间检索增强生成(RAG)技术在软件工程领域的研究进展、应用和挑战:
1. 研究背景与目的
- 背景:随着大语言模型(LLM)的发展,RAG通过结合信息检索和生成模型,显著提升了代码生成、补全、程序修复等软件工程任务的性能。该领域发展迅速,研究者需要全面了解其进展、挑战和机遇。
- 目的:本文旨在对RAG在软件工程中的应用进行系统性综述,汇总并深入分析108篇高质量研究,帮助研究者系统了解现有成果,洞察关键问题,推动领域发展。
2. 研究趋势分析(2021-2024)
- 出版趋势:相关论文数量从2021年的2篇快速增长到2024年的70篇,表明该领域已成为重要研究方向。
- 发表渠道:约67%的论文发表在EMNLP、ICSE、ASE等顶级会议和期刊;33%发表在arXiv预印本平台,反映研究快速扩展。
- 编程语言:Python和Java是最常用的语言(分别占31%和22%),广泛应用于代码生成、修复等任务;其他语言如C/C++、JavaScript等也在特定任务中应用。
- 模型分布:GPT-3.5、Codex、CodeT5等模型被广泛使用;GPT-4、CodeLLaMA等新一代模型在2024年使用显著增长。
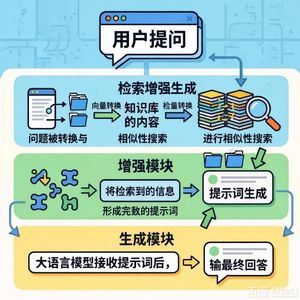
3. RAG核心架构与集成策略
- 检索器组件:稀疏检索器:如BM25,基于关键词匹配,效率高但语义理解弱。
密集检索器:如CodeBERT、GraphCodeBERT,将查询和文档编码为向量,捕捉深层语义。
混合检索器:结合稀疏和密集检索优势,提升检索质量。 - 生成器组件:基于参数微调的生成器:如CodeT5、PLBART,针对特定任务进行监督微调。
基于参数冻结的生成器:如GPT-4、CodeLLaMA,无需额外训练,通过提示工程适应多种任务。 - 集成策略:提示工程:将检索到的信息嵌入提示中,引导生成过程。
模型融合:在模型内部(如通过注意力机制)深度融合检索信息。
迭代的检索-生成循环:根据生成结果动态检索新信息,逐步完善输出。
联合训练:对检索器和生成器进行端到端训练,实现协同优化。
4. RAG在软件工程中的应用
- 软件开发阶段:代码生成:通过检索代码示例、API文档等,生成更准确、符合需求的代码。
代码补全:利用项目上下文和外部知识库,提高补全的准确性和一致性。
代码摘要:检索相关代码或摘要,生成更准确、信息丰富的代码描述。
Text-to-SQL:检索数据库表格和SQL示例,生成正确的SQL查询。
代码翻译:检索跨平台文档,生成高质量的跨平台代码翻译。 - 软件测试阶段:测试生成:检索已有测试用例和代码上下文,生成覆盖全面的测试代码。
漏洞检测:检索历史漏洞案例和修复知识,提高检测准确性和解释能力。
GUI测试:检索GUI控件和交互示例,生成异常输入以触发崩溃缺陷。 - 软件维护阶段:程序修复:检索历史修复补丁和代码上下文,生成准确的修复代码。
漏洞修复:利用模板引导的检索,生成有效的漏洞修复补丁。
代码重构:结合检索和启发式搜索,优化代码结构并保持语义不变。
5. 挑战与未来方向
- 知识库构建:开源代码库质量参差不齐,多样性有限,影响检索和生成效果。未来需构建高质量、广覆盖的代码知识库。
- 检索阶段:检索精度与任务相关性不足,可能返回冗余或无关信息。未来可通过聚类、语义筛选和多阶段过滤优化检索策略,或利用强化学习使检索更符合生成器需求。
- 生成阶段:上下文处理受限:模型上下文长度有限,需通过选择性检索、分层检索、迭代生成和上下文压缩等技术优化。
输出正确性难保证:模型可能产生“幻觉”或生成不可执行代码,尤其在面对未见API或过时知识时。未来需加强提示优化、生成后验证(如语法检测、执行测试),并探索生成-评估-反馈的多轮优化框架。
6. 总结
- RAG技术通过有效融合外部知识与生成模型,在软件工程多个任务中展现出强大潜力,能显著提升代码相关任务的自动化与智能化水平。
- 尽管面临数据质量、检索精度、生成可靠性等挑战,但通过持续优化架构、训练策略和评估方法,RAG有望进一步推动软件工程领域的发展。
以下是各章节的详细解释:
摘要
本章概括了全文的核心内容。它指出,检索增强生成(RAG)通过结合信息检索与大语言模型的生成能力,显著提升了代码生成、补全、程序修复等软件工程任务的性能。由于该领域发展迅速,研究者难以全面掌握。为此,本文对2021年至2024年间的108篇高质量研究进行了系统性综述。主要贡献包括:
- 详细综述:首次系统梳理RAG在软件工程领域的研究。
- 系统回顾:总结RAG的核心架构、关键组件(检索器与生成器)及其集成方式。
- 分类总结:分析RAG在各类软件工程下游任务中的应用、方法与趋势。
- 挑战与展望:讨论当前应用在知识库构建、检索和生成三阶段面临的挑战,并指出未来研究方向。
旨在为社区提供一份全面的参考,推动领域发展。
1. 引言
本章阐述了研究背景和动机。
- 软件工程的重要性:强调软件工程在现代社会各行业中的基础性作用,及其对系统化、可靠软件开发的意义。
- 技术演进:指出预训练语言模型(PLM)和大语言模型(LLM)的出现(如BERT、GPT),为代码理解、生成等任务带来了新机遇。
- RAG的引入:提出RAG框架是高效利用PLM/LLM处理复杂软件工程流程(开发、测试、维护)的新路径。它通过检索器从外部知识库获取相关代码/文档,再由生成器基于此生成新代码或修复方案,从而整合多源知识,提升模型在特定场景下的表现。
- 应用概览与本文贡献:简要列举了RAG在代码生成、程序修复、测试生成等任务中的广泛应用,并再次明确了本文的综述范围和主要贡献。
2. 调研策略
本章说明了文献综述的系统性方法。
- 研究问题:明确了三个核心研究问题(RQ):RQ1:RAG在软件工程中的研究趋势是什么?
RQ2:RAG处理代码任务的检索器和生成器具体结构是什么?
RQ3:RAG在软件工程中的主要应用领域是什么? - 搜索策略:详细描述了文献检索的流程:关键词构建:结合软件工程任务(如代码生成、程序修复)和RAG技术术语。
多库检索:在SpringerLink、ACM、arXiv等主流学术数据库进行检索。
筛选与补充:通过人工筛选确定核心文献,并采用“滚雪球”法(检查参考文献)进行补充,最终确定108篇相关研究。
3. 研究问题1: RAG在软件工程中的研究趋势是什么?
本章通过数据分析回答了RQ1,揭示了领域发展态势。
- 出版时间分布(3.1):论文数量从2021年的2篇快速增长到2024年的70篇,表明该领域自2021年起已成为研究热点,并预计将持续增长。增长驱动力包括模型架构优化、检索技术进步、LLM普及、高质量代码库增多、工业界需求以及活跃的学术社区。
- 出版刊物分布(3.2):约67%的论文发表在EMNLP、ICSE、ASE等顶级会议/期刊(多为CCF A/B类),显示研究质量高且受主流学界认可;其余33%发表在arXiv,体现了研究的快速发展和分享。
- 编程语言分布(3.3):Python(31%)和Java(22%)是最常用的语言,得益于其丰富的数据集和广泛应用。研究也涵盖了C/C++、JavaScript、SQL等多种语言,反映了RAG技术的多语言适应性和任务多样性。
- 模型分布情况(3.4):GPT-3.5是使用最多的生成器模型(38次)。Codex、CodeT5等专用模型持续被采用,而GPT-4、CodeLLaMA等新一代模型在2024年使用显著增长。同时,DeepSeek-Coder等开源模型也开始受到关注。
- 结论(3.5):总结指出RAG在软件工程中的应用研究呈现显著增长、跨学科、聚焦主流语言和模型迭代快速的特点。
4. 研究问题2: RAG处理代码任务的检索器和生成器具体架构是什么?
本章深入剖析了RAG框架的核心技术组件,回答了RQ2。
- 检索器组件(4.1):根据信息表示和相似度计算方式分为三类:稀疏检索器:如BM25,基于关键词匹配,效率高但语义理解弱。
密集检索器:如基于CodeBERT的编码器,将文本编码为向量进行语义匹配,理解力强。可分为使用现成预训练编码器或通过对比学习、强化学习进行任务特定优化的编码器。
混合检索器:结合稀疏与密集检索的优势,先快速筛选再语义排序,提升整体检索质量。 - 生成器组件(4.2):根据是否更新参数分为两类:基于参数微调的生成器:如CodeT5、PLBART,需针对具体任务进行监督微调,在特定任务上性能可能更优。
基于参数冻结的生成器:如GPT-4、CodeLLaMA,作为黑盒模型使用,通过提示工程直接适配多种任务,灵活高效,随着模型能力提升日益流行。 - 检索器和生成器的集成策略(4.3):介绍了四种主要集成方式:提示工程:将检索结果直接嵌入提示词中,简单高效,但对提示设计质量敏感。
模型融合:在模型架构内部(如通过注意力机制)深度整合检索信息,性能可能更优但实现复杂。
迭代的检索-生成循环:根据中间生成结果动态发起新的检索,逐步完善输出,灵活但可能增加耗时。
联合训练:对检索器和生成器进行端到端联合优化,使两者协同演进,需要大量数据和计算资源。 - 结论(4.4):总结了检索器、生成器的不同类型及其集成策略的优缺点,指出这些技术进步共同推动了RAG在软件工程中的有效应用。
5. 研究问题3: RAG在软件工程中的主要应用领域是什么?
本章系统梳理了RAG在软件工程生命周期各阶段的具体应用,回答了RQ3。
- 软件开发:代码生成:通过检索代码示例、API文档、库信息等,为生成器提供丰富上下文,提升生成代码的正确性和实用性。
代码补全:利用检索到的相似代码片段或项目上下文,生成更准确、符合项目规范的补全建议。
代码摘要:检索相关代码或摘要,通过交叉注意力等机制增强模型对代码的理解,生成更准确的摘要。
Text-to-SQL:检索数据库表结构、SQL模板或示例,帮助模型生成正确的SQL查询。
代码翻译:检索跨平台官方文档等资料,为代码翻译提供必要的API和最佳实践上下文。 - 软件测试:测试生成:检索已有测试用例或相关方法,指导模型生成覆盖更全面的测试代码。
漏洞检测:检索历史漏洞案例、修复知识或多样化漏洞样本,增强模型对漏洞模式的理解和检测能力。
GUI测试:检索GUI布局信息、历史崩溃案例等,指导生成能触发异常的测试输入。 - 软件维护:程序修复:检索历史缺陷-修复对或相似代码上下文,帮助模型理解错误模式,生成更准确的修复补丁。
漏洞修复:利用模板引导的检索,从历史漏洞修复库中获取参考,生成有效的修复代码。
代码重构:结合检索到的重构模式和执行反馈,引导模型进行多轮优化,提升重构代码质量。 - RAG应用方式对比分析(5.4):强调软件工程任务的结构性(代码有AST、依赖等结构)和多样性(不同任务需不同知识源,如API文档、测试用例、历史缺陷库),使得RAG的应用需针对任务特性进行专门设计(如图检索、多模态检索等),而非简单套用NLP中的方法。
- 结论(5.5):RAG已广泛应用于软件工程各阶段多种任务,通过整合外部知识显著提升任务性能。LLM作为生成器潜力巨大,而在软件需求、管理等阶段的应用尚处初期,是未来重点。
6. 研究难点与未来挑战
本章总结了当前RAG在软件工程应用中面临的主要挑战及未来方向。
- 知识库构建阶段挑战:开源代码库质量参差不齐,多样性有限,影响检索与生成质量。未来需构建更高质量、覆盖更广的代码知识库和评估基准。
- 检索阶段挑战:如何实现高效、准确且与任务高度相关的检索。稀疏/密集检索各有局限,检索结果可能包含冗余或无关信息。未来可通过引入前/后处理过滤、强化学习优化检索器策略等方法来改进。
- 生成阶段挑战:上下文长度限制:模型处理长文本能力有限。未来可通过选择性检索、分层检索、迭代生成、上下文压缩等策略来优化。
输出正确性与可靠性:模型可能因知识不足或过时产生“幻觉”,生成错误或不可执行的代码。未来可通过优化提示模板、引入生成后验证(如语法检查、测试)、以及采用生成-评估-反馈的多轮优化或协同训练机制来提升。
7. 总结
总结软件工程领域中RAG的研究趋势、技术架构(检索器、生成器及集成策略)以及代码生成、补全、修复等任务实践。讨论了知识库质量、检索效率、生成可靠性等中的挑战。有潜力推动软件开发自动化、智能化
