
 3
3 0
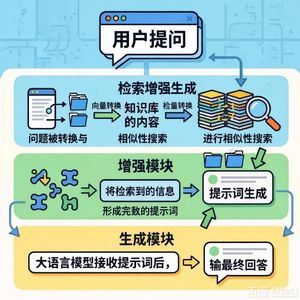
0这篇论文提出了 CODERAG-BENCH,一个用于系统评估检索增强代码生成 的综合性基准测试。其主要内容可总结如下:
1. 核心问题与动机
- 问题:尽管大语言模型在代码生成方面表现出色,但仅依赖其参数化知识难以生成许多复杂程序(如使用不熟悉的库或处理私有代码库)。虽然检索增强生成在文本任务中很成功,但其在代码生成中的应用潜力尚未被充分探索。
- 目标:创建一个统一的基准,以促进对代码导向RAG方法的研究、分析和改进。
2. CODERAG-BENCH 的构成
该基准是一个全栈式测试平台,包含:
- 多样化的编程任务:涵盖四大类六种任务:基础编程:如HumanEval、MBPP,测试算法和内置函数。
开放域编码:如DS-1000、ODEX,需要调用外部库(如pandas, requests)。
仓库级问题:如RepoEval、SWE-bench,需要在完整代码仓库上下文中进行编辑。
代码检索:如CodeSearchNet,直接评估检索质量。 - 大规模的检索数据库:汇集了五种开发者常用资源,共约2500万文档:编程问题解决方案、在线教程、Python库官方文档、StackOverflow帖子、GitHub仓库文件。
- 高质量的标注:为大多数任务手动标注了规范文档(即解决问题所需的关键上下文),用于评估检索质量和RACG性能上限。
- 可复现的评估流程:提供统一的接口,用于检索、增强生成和执行评估(使用pass@k等指标)。
3. 主要实验与发现
论文进行了大规模评估(10种检索器,10种生成模型),关键发现包括:
- 检索能显著提升代码生成:当提供高质量的规范文档时,生成模型(尤其是较弱模型)的性能大幅提升。例如,GPT-4o在SWE-Bench上获得了27.4%的增益。
- 当前RACG系统的两大瓶颈:检索器难以找到有用文档:特别是在开放域和仓库级任务上,检索质量(NDCG@10)普遍较低。
生成模型利用上下文的能力有限:模型容易被不相关文档干扰,或无法有效整合多个文档的信息。上下文窗口较小的模型改进幅度也较小。 - 不同任务的最佳检索来源不同:基础编程:StackOverflow帖子和教程最有帮助。
开放域:对于不常见的库,库文档和编程解决方案能带来最大增益。
仓库级:本地仓库内的代码片段至关重要,外部资源帮助有限。 - 检索模型对比:针对代码训练的密集检索模型(如Jina-v2-code)通常优于通用文本检索模型。
更大的检索模型(如SFR-Mistral)性能更好,但计算和存储成本也显著增加。 - 分块策略的影响:将文档预先分块为200-800个令牌的片段进行检索,通常比检索全文或检索后截断效果更好。
4. 结论与意义
- 结论:检索增强确实有潜力解决代码生成中知识不足的问题,但当前系统在检索和生成两端都存在明显限制,导致RACG结果尚未达到最优。
- 贡献:CODERAG-BENCH为未来研究提供了一个坚实的、可复现的测试平台,旨在推动更强大的代码检索器、能更好利用上下文的生成模型以及更先进的RACG方法的发展。
总之,这篇论文系统地论证了检索增强对于代码生成的价值与挑战,并发布了一个资源丰富的基准来引导该领域的未来研究。
根据提供的文章《CODERAG-BENCH: Can Retrieval Augment Code Generation?》,以下是各章节内容的详细介绍:
摘要
本文介绍了CODERAG-BENCH,一个用于评估检索增强代码生成 的综合性基准测试。尽管语言模型擅长生成代码,但许多程序仅靠模型内部知识难以生成。虽然检索增强生成在文本任务中很成功,但其在代码生成中的潜力尚未被充分探索。为此,本文创建了一个涵盖基础编程、开放域和仓库级问题等多种任务的基准,并提供了一个包含竞赛解决方案、教程、库文档、StackOverflow帖子和GitHub仓库的多样化、开放的代码检索数据库。基于此基准,作者对10个检索器和10个语言模型进行了大规模评估,系统分析了检索何时能有益于代码生成,并指出了剩余的挑战。研究发现,虽然检索高质量上下文能改进代码生成,但检索器常常难以获取有用的上下文,而生成器在有效利用这些上下文方面也存在局限。作者希望CODERAG-BENCH能推动面向代码的RAG方法的进一步发展。
1. 引言
随着语言模型的发展,从自然语言生成代码的能力迅速提升。然而,大多数模型遵循“自然语言到代码”的范式,没有集成外部上下文,这在诸如使用不熟悉的库等复杂场景中至关重要。仅依赖参数化知识也限制了模型在测试时适应新数据分布的能力。检索增强生成通过在推理时检索相关文档来解决这个问题,减少了对模型参数的依赖,并在各种任务中提高了准确性。尽管在基于文本的任务中取得了成功,但其在多样化编码问题和检索源中的应用仍未得到充分探索。本文提出了CODERAG-BENCH,一个旨在推进检索增强代码生成研究的整体性基准。
2. CODERAG-BENCH
本章详细介绍了基准的构建过程,其设计基于三个因素:任务多样性、严谨评估和统一接口。
- 2.1 编程问题:将现有的Python编码数据集分类并整合为四类:基础编程问题、开放域问题、仓库级问题和代码检索问题。每个类别都选取了多个广泛使用的数据集以确保多样性。
- 2.2 检索来源:从开发者常用的五种资源中收集检索文档:编程解决方案、在线教程、库文档、StackOverflow帖子和GitHub文件。基准支持两种检索设置:从规范数据存储中检索,以及从任何数据存储中进行开放检索。
- 2.3 规范文档标注:为确保可靠的检索评估并估计理想检索器下RACG系统的性能上限,为大多数示例手动标注了规范文档——即包含解决编程问题所需必要上下文的文档。
- 2.4 评估指标:对于检索,主要使用NDCG@10进行评估;对于代码生成,使用pass@k指标来衡量程序的执行正确性。
3. 规范RACG评估
本章使用规范数据源对CODERAG-BENCH进行了全面评估,包括文档检索、直接代码生成以及端到端的检索增强生成。
- 3.1 实验设置:采用了10个顶级检索模型和10个生成模型。检索模型涵盖稀疏、稠密和专有API三类;生成模型包括代码专用模型和强大的通用文本模型。
- 3.2 检索结果:分析了不同检索器在各类任务上的表现。发现稠密嵌入模型经常超越传统的BM25基线;专门针对代码检索训练的模型在相似参数量下通常表现更好;更大的检索模型往往带来更好的性能,但也伴随着显著的效率成本。
- 3.3 使用规范文档的生成:评估了模型在不使用检索和使用真实规范文档两种情况下的生成能力。结果显示,提供规范上下文在大多数情况下都能提升性能,尤其是在基础编程问题上。对于使用不常见库的挑战性任务,检索的效果更为明显。
- 3.4 检索增强代码生成:在完整的RACG设置下进行了实验。结果表明,最佳检索模型因任务和底层语言模型而异。在某些情况下,性能最好的检索模型并未带来最佳的RACG结果,这凸显了需要针对多样化任务整体评估RACG系统。
4. 开放检索下的RACG
除了从规范源检索,本章还探索了从所有可用来源进行开放检索的效果,并研究了最佳分块策略。
- 在基础编程问题上,StackOverflow帖子和教程能带来改进,混合多个来源的文档甚至能达到与使用真实文档相当的效果。
- 在开放域问题上,编程解决方案是最有帮助的来源。
- 在仓库级问题上,外部开放资源不如本地仓库中的代码片段有用,理解本地代码上下文至关重要。
- 在分块策略上,研究发现将文档分块到200-800个令牌通常能获得最佳结果,而检索前分块的策略在几乎所有文档源上都取得了最高分。
5. 相关工作
本章回顾了与本研究相关的两个领域:
- 代码生成:神经代码生成已成为一个关键任务,出现了越来越多强大的代码语言模型。然而,大多数模型仅基于自然语言查询和参数知识生成代码,未利用外部编程资源。
- 检索增强生成:RAG已广泛应用于知识密集型任务,但主要集中于使用通用领域语料库的文本中心任务。一些工作使用了从仓库或文档中检索的编程上下文,但尚未有工作考虑跨多样化编码任务和知识源的RACG。
6. 结论
本文提出了CODERAG-BENCH,一个包含各种编码任务和检索源的检索增强代码生成基准。通过对顶级检索和生成模型的实验表明,检索外部文档可以极大地有益于代码生成。然而,当前的检索模型难以找到有用的文档,生成模型的上下文容量和RAG能力也有限,这两者都导致了次优的RACG结果。作者希望CODERAG-BENCH能作为一个坚实的测试平台,推动该领域的未来发展。
