
 4
4 0
0这篇论文题为《量化RAG优势:基于LLM的代码生成多指标基准测试》,旨在评估检索增强生成(RAG)技术对大型语言模型(LLM)在解决编程问题(特别是LeetCode算法题)时性能的影响。以下是主要内容总结:
研究背景与问题
- LLM在代码生成任务中表现出色,但在面对复杂或不熟悉的算法问题时,常出现“幻觉”(生成无效或逻辑错误的代码)和性能下降。
- RAG通过从外部知识库检索相关信息来增强提示,有望弥补LLM的不足,但此前缺乏针对编程问题的系统评估。
方法论
- 数据集:知识库:包含120个LeetCode问题,每个问题配有已验证的代码解决方案和自然语言解释。
测试集:30个未见过的LeetCode问题,用于评估泛化能力。
问题涵盖不同难度(Easy/Medium/Hard)和发布年份,以测试系统鲁棒性。 - 信息检索(IR)系统:使用预训练模型(all-MiniLM-L6-v2)将问题描述转换为向量嵌入。
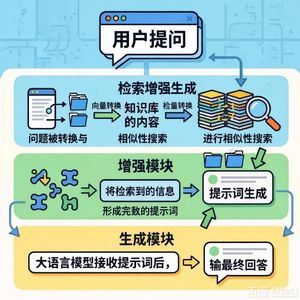
基于FAISS索引和余弦相似度检索相似问题,并采用动态阈值机制(初始阈值65%,根据最高相似度动态调整)来筛选相关上下文。 - 模型选择:评估了六种LLM:GPT-4 omni、Claude 3.7 Sonnet、GPT-3.5 Turbo、Gemini 2.0 Flash、Qwen2.5-Coder-32B和DeepSeek-R1,涵盖通用型、代码专用型及不同能力水平的模型。
- 实验设计:每个测试问题分别用“无RAG”和“有RAG”两种方式处理:RAG版本会检索知识库中最相似的已解决问题,并将其解决方案和解释作为上下文加入提示。
生成的代码通过LeetCode评测系统验证正确性,并记录运行时和内存使用效率(以“超越用户提交的百分比”衡量)。
主要结果
- 正确性提升:多数模型在RAG增强后正确率提高,整体平均提升6.1%。
GPT-3.5 Turbo提升最显著(从50.0%到66.7%),表明RAG对能力较弱的模型帮助更大。
DeepSeek-R1达到最高正确率(96.7%),仅有一个错误。
Gemini 2.0和Qwen2.5-Coder正确率不变,但效率指标改善。 - 效率改进:运行时效率:所有模型均有提升,中位数改善6.3%(如Qwen2.5-Coder从68.9%提升至81.3%)。
内存效率:平均提升11.0%,其中Gemini 2.0从40.1%提升至56.0%。 - 按问题特性分析:难度:Easy问题正确率达100%;Medium和Hard问题也有改善。
发布时间:对2023年后发布的问题改善更明显(正确率从60.4%提升至70.8%)。
结论与未来工作
- RAG能有效提升LLM解决编程问题的正确性、速度和内存效率,尤其对能力较弱的模型或较新问题帮助更大。
- 局限性:仅使用LeetCode单一数据源;未排除“更长提示本身带来提升”的可能性。
- 未来方向:扩展至更多编程平台;增加随机检索基线对比;探索更大知识库的扩展性。
意义
- 为教育领域(如编程学习助手)和代码生成工具提供了改进思路。
- 首次将RAG系统应用于编程问题求解,并引入多维度(正确性、运行时、内存)评估基准。
该研究通过严谨的实验设计,证实了RAG在代码生成任务中的实用价值,并为后续研究提供了可复现的基准框架。
根据提供的文章《Quantifying the RAG Advantage: A Multi-Metric Benchmark for LLM-based Code Generation》,以下是各章节内容的详细介绍:
摘要 (Abstract)
本章概述了全文的核心。它指出,尽管大语言模型在代码生成方面表现出色,但仍存在幻觉问题,且在处理不熟悉或复杂任务时性能有限。检索增强生成通过为提示词补充相关外部信息,成为解决这些限制的有前景方案。本文提出了一个基准测试,通过整合一个包含120个LeetCode问题(每个问题都配有已验证的解决方案和解释)的精选数据库,来评估RAG在解决算法问题上的效能。使用了一个信息检索系统来为求解新问题构建增强提示。
1. 引言 (Introduction)
本章详细阐述了研究背景和动机。尽管LLMs在代码生成任务上能力突出,但在面对复杂算法问题时,经常产生错误或低效的解决方案,这通常源于特定上下文知识的缺乏和对底层数据结构的有限理解,从而导致幻觉。RAG被提出作为一种机制,通过信息检索算法从结构化语料库中检索上下文相似的信息,从而将模型的输出建立在相关外部知识之上。本研究的主要目标是评估RAG是否能提高LLMs解决编程问题的性能。为此,创建了一个包含120个LeetCode问题的数据库作为RAG系统的知识库,并使用基于余弦相似度和动态阈值的IR管道进行检索。在一个独立的、包含30个未见问题的测试集上进行评估,利用LeetCode评测系统验证解决方案的正确性和性能(运行时间和内存使用)。本章强调,这是首次将RAG应用于检索相似示例来解决编程问题的工作,并且评估超越了单纯正确性,还分析了运行效率和问题难度、发布年份的变化对系统鲁棒性的影响。
2. 相关工作 (Related Works)
本章回顾了相关领域的研究。首先总结了多项在没有RAG的情况下评估LLMs解决竞争性编程问题(如LeetCode)能力的研究,本文从这些研究的评估策略和模型选择中汲取了灵感。接着,特别提到了2024年SBBD上的一项类似研究,该研究将RAG应用于提升LLMs在巴西大学入学考试上的表现,其目标(减少幻觉、提高答案可靠性)与本文紧密相关。这些前期工作为本文的研究奠定了基础,例如,本文采纳了相关工作中使用运行时间和内存作为评估指标的建议,并受其按时间和难度划分问题的启发,将这些策略扩展到了RAG的语境中。
3. 方法论 (Methodology)
本章详细说明了实验设计。
- 3.1 信息检索算法:描述了IR系统的具体实现。使用
all-MiniLM-L6-v2模型将问题描述转换为向量嵌入,并使用FAISS(IndexFlatL2)建立索引进行相似度搜索。关键特点是采用了自适应阈值机制:初始相似度阈值为65%,但会根据最高相似度得分动态调整(高于80%则收紧,低于70%则放宽,但不低于65%),旨在减少噪声。 - 3.2 数据集概述:介绍了知识库和测试集的构成。知识库包含120个LeetCode问题,每个条目包括标题、难度、分类、问题文本、已验证的优化代码解决方案和详细解释。测试集包含30个未见过的LeetCode问题,用于公平评估泛化能力。两个数据集的难度分布(简单、中等、困难)和算法类别都经过精心设计,以确保评估的全面性。文中提供了一个表格展示具体分布。
- 3.3 模型选择:说明了选用的六个LLMs:GPT-4o、Claude 3.7 Sonnet、GPT-3.5 Turbo、Gemini 2.0 Flash、Qwen2.5-Coder-32B 和 DeepSeek-R1。选择依据包括它们在先前研究中的使用情况、训练重点的多样性(如代码专用、高级推理、通用目的)以及知识截止日期的不同。
- 3.4 实验:描述了实验流程。每个测试问题都会提交给所有六个LLMs,分别在“无RAG”和“有RAG”两种条件下进行。在RAG条件下,IR系统会从知识库中检索相似问题,并将这些问题的完整信息(包括相似度得分、标题、分类、解决方案代码和解释)整合到最终提示词中。模型生成的代码由LeetCode评测系统验证正确性,并获取其在运行时间和内存使用上超越其他用户提交的百分比排名。
4. 结果与分析 (Results and Analysis)
本章展示了实验结果并进行了深入分析。
- 正确性:数据显示RAG提升了多数模型的正确性。六个模型中有四个在获得增强后正确率提高,其中GPT-3.5 Turbo提升最显著(从50.0%到66.7%)。总体正确率提升了6.1%。Gemini 2.0和Qwen2.5-Coder正确率保持不变,但效率指标有改善。DeepSeek-R1结合RAG取得了最高正确率(96.7%)。文中通过一个表格(图1)直观对比了各模型在有/无RAG时的正确率。
- 效率:RAG显著改善了代码的运算效率。所有模型在运行速度上都有提升,中位数提升6.3%;在内存效率上提升更明显,平均提升11.0%。文中通过另一个表格(图2)展示了各模型在有/无RAG时在速度和内存百分位数上的表现。
- 按问题特性分析:结果还按问题难度和发布年份进行了细分。RAG在简单问题上达到100%正确率,在中等和困难问题上也有提升。对于2023年之后发布的新问题,RAG带来的正确率提升更为明显(从60.4%到70.8%)。文中通过表格(表2)总结了这些跨类别的性能对比。
5. 结论与未来工作 (Conclusion and Future Work)
本章总结了研究发现并展望了后续研究方向。结论指出,本研究提供的证据表明RAG可以提升LLMs解决编程问题的性能,包括正确性、运行时间和内存效率。这对教育等领域具有应用意义。同时,指出了本研究的局限性:仅依赖LeetCode单一数据源可能影响结论的普适性;性能提升可能源于更长的提示词而非检索质量本身。为此,未来的工作方向包括:在更多样化的编程平台上进行评估;引入随机检索问题作为基线进行更严谨的比较;探索使用更大知识库来提升检索质量。
