
 1
1 0
0SolEval是第一个用于评估大语言模型(LLM)在仓库级别生成Solidity智能合约的基准测试:
1. 研究背景与动机
- 问题:LLM在代码生成方面取得了巨大进展,但现有基准(如HumanEval、MBPP)主要关注Python、Java等主流语言,严重缺乏对Solidity(以太坊主要智能合约语言)的评估。
- 挑战:Solidity开发受gas费用(执行成本)和区块链不可变性的约束,使得代码生成比通用编程语言更具挑战性。
- 现有工作的不足:此前唯一的Solidity基准BenchSol规模极小(仅15个用例),且仅评估独立函数生成,与需要处理跨文件依赖的真实世界仓库级开发场景脱节。
2. SolEval基准的构建
- 规模与来源:包含 1,125个样本,源自 9个真实世界的开源Solidity仓库,覆盖安全、金融、游戏等 6个流行领域。
- 关键特性:仓库级评估:重点关注非独立函数的生成,要求模型理解并利用来自其他文件的上下文依赖(如接口、变量、函数)。
人工标注:由5名有经验的硕士生对函数需求(注释)进行手动标注,以减少LLM的记忆效应并提供高质量描述。
全面评估指标:不仅评估功能正确性,还引入了对智能合约至关重要的质量属性:功能正确性:使用Pass@k和Compile@k指标。
Gas费用:衡量生成合约的执行成本。
漏洞率:使用Slither工具检测生成代码中的安全漏洞。 - 构建流程:包括项目筛选、函数解析、测试构建、人工标注和上下文解析五个阶段,确保数据的多样性、真实性和可评估性。
3. 实验评估与主要发现
对 10个主流LLM进行了评估,并探究了以下研究问题:
- RQ1:整体性能如何?所有模型在Solidity代码生成上表现远未达到理想水平。性能最佳的DeepSeek-V3的
Pass@10也仅为 26.29%,表明有巨大改进空间。
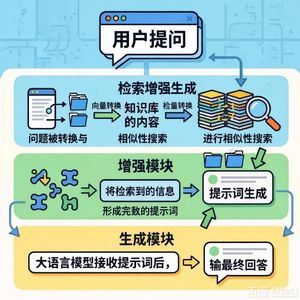
存在正确性与Gas效率的权衡:例如,DeepSeek-V3正确率最高但Gas费用也高;而DeepSeek-R1-Distill-Qwen-7B正确率最低但生成的合约最省Gas。 - RQ2:不同配置如何影响效果?RAG(检索增强生成)和上下文信息能有效提升模型的功能正确性(
Pass@1和Compile@1)。
更大的模型不一定生成更省Gas的代码(例如,GPT-4o-mini在Gas优化上优于GPT-4o)。
提供过多的示例(few-shot)会导致输入长度和耗时大幅增加,但性能提升有限。
4. 贡献总结
- 指出局限:明确了现有Solidity基准在规模和真实性方面的不足。
- 提出新基准:发布了首个大规模、仓库级的Solidity智能合约生成基准SolEval,包含丰富的真实样本和关键的质量评估维度(Gas、漏洞)。
- 全面评估:对10个SOTA LLM进行了广泛评估,揭示了它们在Solidity生成上的性能差距,并验证了RAG和上下文信息的有效性。
5. 未来工作与局限
- 未来方向:扩展更多仓库和测试用例;支持多语言(如Vyper、Rust)评估。
- 当前局限:仅支持Solidity单语言;因资源未评估某些最新模型;Gas和漏洞指标仅用于评估,未提供优化方法。
以下是每一章节的详细介绍:
摘要 (Abstract)
- 核心内容:介绍了研究背景、问题陈述和主要贡献。
- 详细说明:指出大型语言模型(LLMs)在代码生成方面取得了变革性进展,但现有研究主要集中在Python、Java等主流语言,忽视了以太坊智能合约的主要语言Solidity。由于缺乏足够的Solidity基准测试,LLMs生成安全、经济高效的智能合约的能力尚未得到充分探索。为此,作者构建了SolEval,这是第一个为Solidity智能合约生成设计的仓库级(repository-level)基准测试。SolEval包含来自9个不同仓库的1125个样本,覆盖6个流行领域,并引入了燃气费(gas fee) 和漏洞率(vulnerability rate) 这两个关键现实属性。对10个LLMs的评估结果显示,表现最佳的模型Pass@10也仅为26.29%,表明LLMs在Solidity代码生成方面仍有巨大改进空间。
1. 引言 (Introduction)
- 核心内容:阐述了研究动机、现有工作的局限性以及SolEval的必要性。
- 详细说明:随着区块链和去中心化金融(DeFi)的快速发展,智能合约部署激增,对高效可靠的Solidity代码生成工具需求迫切。LLMs已成为代码生成的主导方法,但现有基准测试(如HumanEval, MBPP, ClassEval)大多关注Python和Java。Solidity语言因其受燃气费和区块链不可变性的约束,代码生成更具挑战性。现有的Solidity基准测试BenchSol规模极小(仅15个用例),且由GPT-4生成,与真实场景脱节,仅支持独立函数评估。为了填补与现实世界对齐的Solidity基准测试空白,作者提出了SolEval,它是第一个支持仓库级智能合约生成的基准测试,包含非独立函数(依赖仓库上下文),并具有规模大、人工标注、包含关键质量属性(燃气费、漏洞率)等特点。
2. 基准测试 - SolEval (Benchmark - SolEval)
- 核心内容:详细描述了SolEval基准测试的设计、输入输出和评估指标。
- 详细说明:2.1 概述 (Overview):SolEval包含1125个样本,来自9个真实代码仓库,覆盖6个领域。其设计用于评估LLMs在仓库级智能合约生成上的性能,包含两个关键阶段:(1) 基于LLM的Solidity代码生成 和 (2) 后生成评估。
2.2 基于LLM的Solidity代码生成 (LLM-based Solidity Code Generation):LLM接收的输入包括:① 函数签名、② 需求(自然语言描述)、③ & ④ 仓库上下文(被引用代码的接口、函数、变量等)。LLM根据这些输入生成目标函数。
2.3 后生成评估 (Post-Generation Evaluation):使用Forge工具执行测试用例进行评估。评估指标包括:功能正确性:Pass@k(至少有一个生成样本通过测试的比例)和 Compile@k(至少有一个生成样本编译成功的比例)。
质量属性:燃气费 (Gas Fee)(执行测试的燃气消耗,与原始函数对比)和 漏洞率 (Vul)(使用Slither静态分析工具检测出的高风险漏洞比例)。
3. 基准构建 (Benchmark Construction)
- 核心内容:详细说明了SolEval数据集的构建流程,包括五个关键阶段。
- 详细说明:3.1 项目选择 (Project Selection):从OpenZeppelin等6个流行GitHub组织中筛选高质量、有测试用例的Solidity项目仓库。
3.2 函数解析 (Function Parsing):设计Solidity版本的Tree-sitter来解析合约,提取函数信息,并过滤掉测试函数、接口和过短的函数,最终得到1125个函数样本。
3.3 测试构建 (Test Construction):收集并确保每个函数有完整的单元测试覆盖(包括模糊测试、不变性测试等),并建立函数与测试用例的映射关系以提高评估效率。
3.4 人工标注 (Human Annotation):招募5名有至少3年Solidity经验的硕士生对函数需求进行人工标注,以减少LLM的“记忆效应”并提供高质量注释。使用Fleiss‘ Kappa评估标注者间的一致性,结果优秀。
3.5 上下文解析 (Context Parsing):通过静态程序分析识别每个函数所依赖的上下文(如外部调用的函数签名、变量等),这是SolEval与BenchSol的关键区别之一,有助于避免编译错误并验证模型对需求的理解。
4. 实验设置 (Experimental Setup)
- 核心内容:介绍了评估所使用的大型语言模型、评估方法以及研究问题。
- 详细说明:
研究问题:RQ-1 整体正确性:LLMs在Solidity代码生成上表现如何?
RQ-2 敏感性分析:不同配置如何影响LLMs的有效性?
4.1 研究的LLMs (Studied LLMs):选择了10个最先进的LLMs,包括闭源模型(如GPT-4o, GPT-4o-mini)和开源模型(如CodeLlama, DeepSeek-Coder),涵盖不同规模(6.7B到671B参数)和类型(通用LLM和代码专用LLM)。
4.2 评估方法与指标 (Evaluation Methodology and Metrics):采用Pass@k和提出的Compile@k作为主要指标(k=1,5,10)。同时评估燃气费和漏洞率。实验还使用了检索增强生成(RAG) 技术来选取最佳示例。所有实验结果均为5次独立运行的平均值。
5. 结果 (Results)
- 核心内容:展示了实验结果并回答了研究问题。
- 详细说明:
5.1 RQ-1:LLMs在Solidity代码生成上表现如何?功能正确性:在评估的10个LLMs中,DeepSeek-V3 (671B) 表现最佳,Pass@10达到26.29%,但整体水平仍较低,表明LLMs生成正确的Solidity合约(尤其是非独立函数)非常困难。不同规模的模型内部比较显示,Qwen2.5-Coder在32B-34B模型中领先。
质量属性:不同LLM生成的合约在燃气费和漏洞率上差异显著。例如,DeepSeek-V3正确率最高,但生成的合约燃气效率较低;而GPT-4o-mini正确率低于GPT-4o,但生成的合约燃气费更低。这揭示了功能正确性与燃气效率之间的权衡困境。
5.2 RQ-2:不同配置如何影响LLMs的有效性?示例数量的影响:增加提示中的示例数量会显著增加平均令牌长度和运行时间,但对Pass@k的提升有限。因此,后续实验采用单样本(one-shot) 设置。
选择策略的影响:使用RAG检索相关示例比随机选择示例能带来更高的Pass@1和Compile@1,表明RAG能提升代码生成效果。
上下文信息的影响:为LLM提供函数所需的上下文信息能提高Pass@1和Compile@1,但对燃气费和漏洞率没有明显影响。
5.3 经验教训 (Empirical Lessons):RAG和上下文信息能提升LLMs在Solidity合约生成上的性能。
LLMs有时能在复杂需求上生成优秀合约,却可能在简单问题上失败。
更大的语言模型不一定能改善生成代码的燃气费。
6. 相关工作 (Related Work)
- 核心内容:回顾了与本研究相关的两大领域工作。
- 详细说明:6.1 大型语言模型 (Large Language Model):概述了代码生成LLMs(如CodeLlama, Magicoder, DeepSeek-Coder)的发展,以及针对主流语言的提示工程优化技术(如思维链、自我调试)。
6.2 代码生成基准测试 (Code Generation Benchmark):总结了针对主流语言(如Python, Java)的基准测试(如HumanEval, MBPP, DS-1000, Concode),并指出它们对Solidity语言的忽视。同时指出,BenchSol是此前唯一的Solidity基准测试,但其在规模、真实世界对齐和任务类型(仅限独立函数)上存在严重局限。
7. 结论与未来工作 (Conclusion and Future Work)
- 核心内容:总结了研究贡献,并提出了未来的研究方向。
- 详细说明:本文提出了SolEval,这是第一个用于评估LLMs在Solidity智能合约生成场景下有效性的仓库级基准测试。与BenchSol相比,SolEval在任务规模(75倍)、真实世界代码对齐以及关键属性评估(燃气费、漏洞率)方面具有显著优势。实验揭示了当前最先进LLMs在生成非独立Solidity函数方面的局限性。未来工作有两个方向:1) 从GitHub寻找更多高质量仓库,扩大数据集;2) 支持更多编程语言,使其成为多语言基准测试。
