
 4
4 0
0这篇题为《预上下文生成:提升生成式AI代码生成效率的关键》的论文,核心论点是:生成式AI(特别是大语言模型)在代码生成任务中,因其逐字符(token-by-token)的自回归生成机制,在面临大规模、复杂代码库时,若每次都需实时处理全部上下文,将导致严重的效率瓶颈。为解决此问题,报告系统性地提出了以 “预上下文生成” 为核心的工程化解决方案。
论文的主要内容可总结如下:
1. 核心问题分析
- 效率瓶颈:LLM的逐字符生成方式及标准注意力机制的二次方计算复杂度,使得实时处理大型代码库上下文成本高昂,导致生成速度慢、资源消耗大。
- 上下文限制:有限的上下文窗口使模型难以捕捉代码中的远程依赖关系,影响生成代码的质量和准确性。
- 数据挑战:海量且质量参差不齐的文档和代码库,进一步加剧了即时处理的困难和输出结果的不确定性。
2. 核心解决方案:预上下文生成
- 核心理念:将必要、常用的上下文信息(如项目结构、API文档、编码规范)预先处理、结构化并存储,在代码生成时进行高效检索和利用,避免重复的实时计算。
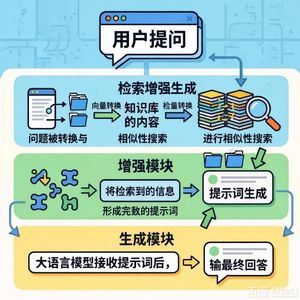
- 基础方法:检索增强生成(RAG) 是实现预上下文生成的 foundational 方法。它通过外部知识库的索引与检索,为LLM提供相关的预生成上下文,从而提升生成效率和质量。
- 高级优化:报告详细阐述了超越基础RAG的高级技术,包括:预检索优化:如代码语义分块、添加元数据、使用LLM提高信息密度。
精密检索策略:如混合搜索、查询路由、图搜索。
后检索优化:如重排序、上下文蒸馏、纠正性RAG(CRAG)以过滤低质量内容。
生成优化:如思维链提示、自适应RAG。
3. 补充与替代技术
- 缓存与预计算:利用KV缓存、更高级别的上下文缓存(如Gemini上下文缓存)以及缓存增强生成(CAG) 来存储和复用预计算的状态,进一步提升效率。
- 模型架构优化:探讨了如Latte、Fast Multipole Attention等旨在降低Transformer计算复杂度的新架构,以及知识蒸馏技术,用于创建更小巧、高效的领域特定代码模型。
- 系统架构:强调了构建以预上下文为核心的可扩展AI系统架构的重要性,包括模块化设计、数据处理流水线,并介绍了动态知识图谱作为管理复杂代码上下文的先进形式。
4. 实践案例
- 报告分析了DeepWiki、Context7和DeepWiki-Open等实际系统,展示了预上下文生成(主要通过RAG架构)在将代码库转换为交互式知识库、为AI编码助手提供精准上下文等方面的具体应用,验证了其有效性。
5. 综合建议与未来展望
- 报告最后为构建高性能AI代码生成系统提出了综合建议,强调需根据场景(动态/静态代码库、资源限制等)混合搭配RAG、微调、缓存、蒸馏等技术。
- 提出了管理数据质量、减轻幻觉、保障安全与知识产权的最佳实践。
- 展望了未来趋势,如更深度的知识图谱集成、自我改进系统、多模态上下文以及形式化验证等。
总之,论文主张通过工程化的“预上下文生成”策略,将AI代码生成从依赖即时上下文处理的模型,转向集成了智能化上下文预生成、管理和高效检索的情境感知系统,从而实现显著的效率与质量提升。
以下是报告各章节的详细内容介绍:
I. 瓶颈解析:理解缺乏预上下文时生成式AI在代码生成中的低效性
本章深入剖析了问题的根源。首先,它指出生成式AI(特别是LLM)固有的自回归、逐字符生成机制是效率低下的核心。标准Transformer的注意力机制具有二次方计算复杂度,处理长代码序列成本高昂。其次,海量且质量参差不齐的文档和代码库给即时处理带来巨大挑战,可能导致模型从低质量样本中学习,产生不安全或有缺陷的代码。最后,本章强调高质量的上下文理解对于生成正确、相关的代码至关重要,而缺乏预生成机制会导致模型重复计算、丢失远程依赖关系,并可能产生“幻觉”。
II. 检索增强生成(RAG):实现预上下文生成的foundational方法
本章将RAG定位为实现预上下文生成的基础方法。它详细阐述了RAG的核心机制:
- 数据准备与分块:将源代码和文档进行预处理和分块,特别强调了针对代码的语义分块(按函数、类等自然边界分割)以保持上下文完整性。
- 嵌入与向量存储:使用嵌入模型将文本/代码块转换为向量,并存储在向量数据库中,以实现基于语义相似性的高效检索。
- 检索与生成:根据用户查询检索最相关的预生成上下文块,并将其注入提示中供LLM生成最终代码。
本章还重点讨论了上下文充分性的重要性,并引用了一个关键表格,展示不同LLM在预生成上下文“充分”与“不足”时的性能差异,突出说明了即使强大模型在上下文不足时也容易产生自信的错误。
III. RAG进阶:优化预上下文处理的高级技术
本章介绍了超越基础RAG、进一步优化预上下文处理流程的高级技术,并将其分为四个阶段:
- 预检索优化:在索引前提升预生成数据的质量,如添加元数据、使用LLM提高信息密度、进行语义分块和假设性问题索引(HyDE)。
- 精密检索策略:采用更智能的检索方法,如混合搜索(结合关键词与语义)、查询路由、分层检索和自查询检索。
- 后检索优化:对检索到的上下文进行再处理,如重排序、上下文压缩/蒸馏,以及使用纠正性RAG(CRAG)进行质量评估与过滤。
- 生成阶段优化:通过思维链提示、少样本提示等技术,引导LLM更好地利用优化后的预生成上下文进行生成。
本章通过一个表格总结了各阶段关键技术及其对代码生成(尤其是处理质量不均文档时)的益处。
IV. 上下文高效处理的预计算、缓存与字符优化
本章探讨了除RAG外,其他提升上下文处理效率的补充策略:
- 上下文学习与预训练:通过提示中的示例(上下文学习)或在领域数据上微调,将知识预置到模型中。
- 上下文缓存:介绍了Transformer中的KV缓存技术以加速生成,并指出了其内存消耗大以及压缩技术可能损害代码远程依赖的问题。同时介绍了更高级的上下文缓存服务(如Gemini上下文缓存),可重复使用预加载的上下文以降低成本。
- 缓存增强生成:介绍了CAG作为RAG的替代方案,它一次性将所有静态知识库预加载到模型缓存中,消除了实时检索步骤,在特定场景下速度更快、架构更简单。
- 字符优化:讨论了通过提示工程、响应流式传输、智能上下文剪枝等手段,优化字符使用以控制成本和提升效率。
V. 构建处理大型代码库的稳健AI系统架构:支持高效的预上下文生成与利用
本章从系统架构角度,探讨如何构建支持预上下文生成与利用的稳健系统:
- 设计原则:包括模块化、可扩展的数据处理流程、持续学习与更新机制,以及平衡性能与成本。
- 关键架构模式:重点介绍了Copilot模式,即如何将LLM与RAG、技能集成等组件结合,构建上下文感知的辅助编程应用。
- 动态知识图谱:提出将知识图谱作为更丰富、结构化的预计算上下文形式,用于建模代码实体间的复杂关系,从而增强RAG的推理能力和可解释性。
- 上下文窗口管理:讨论了如何通过缓存、自适应注意力机制和RAG本身,来优化对有限上下文窗口的利用。
VI. 标准RAG的替代与补充方案探索:进一步提升预上下文利用效率
本章视野更广,探讨了可替代或补充RAG的其他技术路线:
- Transformer架构优化:研究如Latte、Fast Multipole Attention、AnchorCoder等新架构,旨在从根本上降低注意力机制的计算复杂度,使其能更高效地处理预生成上下文。本章通过一个表格对比了这些优化技术。
- 知识蒸馏:将大型“教师”模型的知识迁移到小型“学生”模型,以创建更轻量、高效的领域专用代码模型。
- 受控生成与增量生成:通过将编程语言语法等规则作为预设上下文,引导LLM输出符合语法、无错误的代码。
- 战略性微调:比较了微调主LLM与微调RAG嵌入模型的不同策略,以及它们与RAG的适用场景。
- 专业化RAG架构:介绍了针对不同数据类型的结构化RAG、API增强RAG和基于知识的RAG。
VII. 上下文代码理解与生成案例研究:预上下文生成的实践应用
本章通过三个实际案例,展示了预上下文生成理念的应用:
- DeepWiki (Cognition Labs):商业工具,自动将GitHub代码库转换为交互式AI维基,其问答和深度研究功能依赖于对代码库的预先分析和索引。
- Context7 (Upstash):专注于为AI编码助手提供高质量、版本化的预生成代码上下文库(通过
llms.txt格式),旨在减少因API知识过时而产生的幻觉。 - DeepWiki-Open:DeepWiki的开源实现,其架构明确包含RAG模块(
rag.py)和数据预处理管道,依赖于预生成的代码嵌入和文档。
这三个案例共同验证了基于RAG的预上下文生成是解决代码库理解与生成效率问题的有效工程路径。
VIII. 综合解决方案:构建以预上下文为核心的高性能AI代码生成系统
本章是全报告的总结与集成,提出了构建高性能系统的综合建议:
- 战略选择:强调没有单一最佳方案,应根据代码库的动态性、资源限制、精度要求等具体场景,在RAG、缓存(CAG)、微调和模型架构优化之间做出权衡或组合使用。
- 最佳实践:给出了管理大型、异构代码库的具体操作建议,包括稳健的数据预处理、代码感知分块、丰富元数据提取、实施混合搜索与CRAG等质量过滤机制,以及建立定期的预生成上下文库更新流程。
- 风险缓解:讨论了如何通过高质量的预生成上下文、上下文充分性评估、生成后验证、安全扫描集成以及严格的访问控制,来减轻幻觉、安全性和知识产权风险。
- 未来展望:指出了知识图谱更深集成、自我改进系统(自适应RAG)、多模态上下文、专门化小型代码模型等前沿方向。
报告最后通过一个综合性对比表格,从效率、复杂性、可扩展性、成本等维度,系统比较了基础RAG、高级RAG、微调、知识蒸馏等多种技术的特性与适用场景。
总结而言,这份报告系统性地论证了“预上下文生成”作为解决生成式AI代码生成效率瓶颈的核心工程策略。它从问题分析、基础方法(RAG)、高级优化、架构设计、替代方案、实践案例到综合构建方案,提供了一个完整的知识框架,最终导向一个结论:未来的高性能AI代码生成系统,必然是集成了智能化上下文预生成、管理和高效检索能力的工程化、情境感知系统。
