
 2
2 0
0根据提供的论文《RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems》,其主要内容总结如下:
1. 核心目标与动机
论文旨在解决当前缺乏一个能够全面、可配置地评估检索增强生成(RAG)系统端到端性能和质量的基准测试框架的问题。现有基准大多只关注语义质量或孤立组件的性能,无法捕捉真实部署中全流程的系统行为、资源竞争和配置权衡。因此,作者提出了RAGPerf框架。
2. RAGPerf框架的核心设计
RAGPerf是一个模块化、可扩展的端到端基准测试框架,其主要设计特点包括:
- 模块化流水线:将RAG工作流解耦为独立的、可配置的组件,包括数据嵌入(Embedding)、索引(Indexing)、检索(Retrieval)、重排序(Reranking)和生成(Generation)。
- 可配置性:允许用户灵活配置每个组件的核心参数(如嵌入模型、向量数据库类型、索引方法、LLM模型、批处理大小等),并研究它们对端到端性能和查询质量的影响。
- 真实工作负载生成:内置工作负载生成器,支持多种数据集(文本、PDF、代码、音频)、不同的查询/更新比例、查询分布(均匀分布、Zipfian分布),以模拟真实场景中知识库的动态更新和访问模式。
- 自动化指标收集:性能指标:端到端查询吞吐量/延迟、主机/GPU内存占用、CPU/GPU利用率、I/O吞吐量等。
质量指标:通过集成Ragas框架,自动评估上下文召回率(Context Recall)、查询准确性(Query Accuracy)和事实一致性(Factual Consistency)。 - 低开销分析:采用独立的系统性能监控器,在引入可忽略性能开销(论文评估为~0.11%)的情况下,进行细粒度的系统和组件级性能剖析。
3. 实现与支持
- 实现语言:Python。
- 支持范围:数据集:Wikipedia、ArXiv、GitHub代码、People‘s Speech音频等。
模型:多种嵌入模型(如all-MiniLM-L6-v2)、重排序模型(如BGE)和生成LLM(如Qwen、Llama系列)。
向量数据库:LanceDB、Milvus、Qdrant、Chroma、Elasticsearch。
多模态支持:提供针对PDF/图像(OCR或ColPali直接编码)和音频(ASR转录)的专用处理流程。
4. 评估验证
论文通过一系列实验证明了RAGPerf的能力:
- 端到端性能剖析:识别不同模态(文本、PDF、音频)RAG流水线的瓶颈(如文本流水线中LLM生成是主要瓶颈)。
- 资源利用分析:揭示不同阶段对GPU计算、CPU、主机内存和I/O等资源的需求差异。
- 准确性评估:展示生成模型的能力(而非向量数据库)对最终答案质量起主导作用,且高检索召回率不一定能转化为高答案准确性。
- 更新操作影响:量化了知识库持续更新对查询延迟和准确性的影响,以及临时平面索引(flat index)策略的权衡。
- 配置敏感性分析:分析了批处理大小、嵌入维度、索引方法等参数对性能和资源消耗的影响,为系统调优提供数据支持。
5. 结论与贡献
RAGPerf填补了RAG系统端到端基准测试的空白。它帮助开发者和研究人员理解复杂的RAG流水线在不同配置和工作负载下的系统行为与性能瓶颈,从而做出数据驱动的优化和部署决策。论文已将RAGPerf开源。
根据提供的文章《RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems》,以下是各章节内容的详细介绍:
摘要
本文介绍了RAGPerf的设计与实现,这是一个用于表征RAG(检索增强生成)管道系统行为的端到端基准测试框架。为了便于详细分析和细粒度性能剖析,RAGPerf将RAG工作流解耦为几个模块化组件:嵌入、索引、检索、重排序和生成。它允许用户灵活配置每个组件的核心参数,并检查它们对端到端查询性能和质量的影响。RAGPerf包含一个工作负载生成器,通过支持多样化的数据集、不同的检索与更新比例以及查询分布来模拟真实场景。它还支持不同的嵌入模型、主流向量数据库以及用于内容生成的不同大语言模型。该框架自动化收集性能指标和准确性指标。通过一系列综合实验展示了其能力,并在GitHub上开源了代码库。评估表明,RAGPerf带来的性能开销可以忽略不计。
1. 引言
本章阐述了大型语言模型(LLM)的局限性,特别是在需要领域特定知识或私有数据的场景下。检索增强生成(RAG)技术被提出以解决此问题。然而,部署RAG管道时,理解其系统瓶颈和设计权衡至关重要。由于整个RAG管道计算栈的复杂性,研究其在实际部署场景下的性能影响和查询质量非常困难且耗时。现有的RAG基准测试大多关注特定应用的语义指标,很少研究RAG管道的性能行为,且缺乏灵活性。受YCSB等云服务基准框架的启发,本文提出了RAGPerf,旨在为RAG生态系统提供一个专用的端到端基准测试框架。
2. 背景与动机
本章分为三个小节:
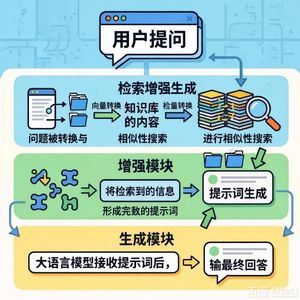
- 2.1 RAG-based AI系统架构:详细描述了典型RAG系统的三个阶段:索引(将原始数据分块、嵌入并存入向量数据库)、检索(将用户查询编码为向量并进行相似性搜索,可能包括重排序步骤)和生成(将查询和检索到的上下文组合成提示,交由LLM生成最终响应)。
- 2.2 RAG应用:总结了RAG在不同领域的流行应用,包括对话式AI、企业智能(如法律、金融、医疗)和多模态语义搜索(如视频、图像、会议摘要)。这些应用对底层硬件资源的需求和瓶颈各不相同。
- 2.3 RAG系统基准测试:分析了现有RAG基准测试的不足:要么只关注语义指标而忽略系统效率,要么只评估单个组件(如向量数据库或LLM),无法捕捉全集成管道中的运行时性能干扰和资源争用,且通常缺乏可配置性。这构成了开发RAGPerf的动机。
3. 设计与实现
本章详细阐述了RAGPerf的设计目标和具体实现:
- 3.1 RAGPerf的目标:包括端到端评估、模块化与易用性、低开销剖析、工作负载多样性以及可扩展性和可移植性。
- 3.2 工作负载生成器:为了模拟真实世界知识库的动态更新,RAGPerf生成并发的读写请求。它支持四种基本操作:查询、插入、更新和删除。用户可以配置操作的发生概率和访问分布(均匀分布或Zipfian分布)。对于更新操作,RAGPerf使用基于LLM的生成模块来合成事实更新及其对应的问答对,以验证更新后的知识库。
- 3.3 可配置的RAG管道:RAGPerf将管道分解为可独立配置的模块:嵌入:支持不同的分块策略(固定长度、基于分隔符、基于语义)、文档格式处理(纯文本提取或OCR)以及多种嵌入模型(包括多模态模型)。用户可以配置硬件资源分配。
向量数据库与索引:通过DBInstance抽象层支持多种向量数据库。允许配置不同的索引方法、量化方案和更新策略(如使用临时平面索引来吸收增量更新)。
重排序:通过BaseReranker抽象层支持不同的重排序模型和策略,并允许配置初始检索深度。
生成:使用vLLM作为默认的LLM后端,支持多种LLM和并行策略(数据并行、张量并行、流水线并行)。 - 3.4 性能与质量指标:性能指标:通过一个解耦的资源监控器收集细粒度的硬件资源利用率(CPU/GPU利用率、内存占用、I/O吞吐量)和端到端性能指标(延迟、吞吐量)。
质量指标:集成Ragas框架,在负载执行后评估生成质量,包括上下文召回率、事实一致性和查询准确性。 - 3.5 RAGPerf实现:框架使用Python实现,基于HuggingFace生态系统,支持多种向量数据库,使用vLLM作为LLM服务后端,并利用容器化工具管理依赖。监控子系统实现为一个多线程守护进程。
4. 基准测试工作负载
本章定义了RAGPerf默认包含的一组代表性工作负载:
- 4.1 数据集:涵盖多种模态和结构复杂性,包括Wikipedia(文本)、ArXiv(PDF)、GitHub代码和The People‘s Speech(音频)。
- 4.2 模型:支持涵盖嵌入、重排序和生成整个管道的综合模型集,包括通用模型和针对编码、数学、视觉理解等领域的专用模型。
- 4.3 向量数据库:支持LanceDB、Milvus、Qdrant、Chroma和Elasticsearch,并支持多种索引方法。
- 4.4 多模态检索:为视觉和音频数据实现了独立的默认处理管道,例如使用OCR或直接视觉嵌入处理PDF/图像,使用ASR转录处理音频。
5. 评估
本章通过实验展示了RAGPerf的能力:
- 5.1 实验设置:描述了测试平台的硬件、软件和数据集配置。
- 5.2 端到端性能:对文本和PDF管道进行了延迟分解分析。结果显示,对于文本查询,LLM生成是主要瓶颈;对于PDF管道,重排序可能成为主导;索引阶段,格式转换(如OCR)和数据库插入是主要开销来源。
- 5.3 资源利用率分解:展示了RAGPerf细粒度剖析资源使用的能力。不同阶段瓶颈不同:嵌入和生成阶段受GPU计算限制,检索和索引构建阶段CPU利用率高,插入阶段主机内存和磁盘I/O成为瓶颈。
- 5.4 准确性评估:评估了不同配置下的RAG质量。发现整体质量主要由生成模型决定,而非向量数据库。同时指出,高上下文召回率并不总能保证高准确性,因为小模型可能缺乏有效利用检索上下文的能力。
- 5.5 更新操作:评估了在持续文档更新下的性能。展示了使用临时平面索引可以在保证数据新鲜度(提高准确性)和查询延迟增长之间的权衡,以及更新分布(Zipfian vs 均匀)对性能的影响。
- 5.6 多样化资源配置的影响:量化了不同系统资源配置(CPU核心数、主机内存、GPU内存)对RAG性能的影响。发现GPU内存是主要硬件瓶颈,主机内存不足会严重降低吞吐量,而CPU核心数影响相对较小。
- 5.7 敏感性分析:分析了关键管道参数的影响,包括批处理大小、嵌入维度和向量数据库索引类型。展示了这些参数在吞吐量、内存使用和检索质量之间的权衡。
- 5.8 开销分析:表明RAGPerf的剖析功能引入的开销可以忽略不计(仅增加约0.11%的迭代时间),且自身资源消耗极低。
6. 相关工作
本章将相关工作分为三类:
- RAG基准测试:回顾了专注于语义质量评估或单个组件性能评估的现有基准,指出它们与RAGPerf的端到端、可配置、系统级评估定位不同。
- RAG系统优化:概述了旨在优化RAG系统性能的研究工作,指出RAGPerf可以作为一个促进此类优化的易用框架。
- RAG扩展:提到了扩展RAG范式的新机制,并指出RAGPerf的模块化设计可以支持此类扩展。
7. 结论
总结了RAGPerf作为一个端到端RAG管道基准测试框架的价值,它能够帮助开发者识别性能瓶颈、探索设计权衡,并以可忽略的开销提供详细的系统剖析。
