
 14
14 0
0这篇题为《基于大语言模型(LLM)与检索增强生成(RAG)融合机制的面向编辑辅助决策的可解释审稿人推荐方法》的论文,其主要内容总结如下:
1. 研究背景与问题
- 背景:在科技期刊稿件量增长的背景下,快速、精准地找到合适的审稿人对保证评审质量和出版效率至关重要。
- 现有方法不足:传统的审稿人推荐方法(如基于协同过滤或基于内容语义匹配的方法)存在局限性,包括:难以处理跨学科或新兴主题、可能导致审稿人负载不均衡、以及推荐结果缺乏可解释性。直接使用大语言模型(LLM)则存在“幻觉”(生成虚假信息)和知识更新滞后的问题。
2. 提出方法
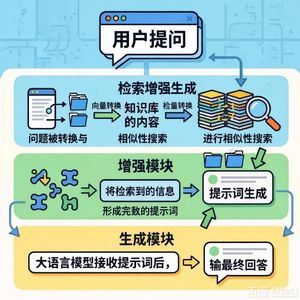
- 核心方案:为解决上述问题,本研究设计并实现了一个智能审稿人推荐系统(IRRS)。该系统创新性地融合了大语言模型(LLM)与检索增强生成(RAG)技术。
- 核心思路:利用RAG技术引入外部知识库(本研究使用Web of Science文献元数据构建),为LLM提供准确、最新的学术信息约束,从而减少幻觉。同时,通过精心设计的双层提示词框架,引导LLM基于检索到的信息生成候选审稿人名单及可解释的推荐理由。
3. 系统设计与流程
- 系统架构:IRRS包含三层:数据层:负责采集和清洗WoS元数据。
知识表征层:使用关系数据库和向量数据库共同存储和管理数据,其中向量数据库用于高效的语义相似度检索。
智能推荐层:核心流程包括:将待审稿件向量化 → 从向量库中检索语义相似的Top-N文献 → 提取这些文献的作者作为候选审稿人 → 进行利益冲突检测 → 利用双层提示词框架引导LLM生成排序后的推荐列表及理由。
4. 实验与效果评估
- 实验设置:以期刊 Intelligent Computing 2025年的20篇已发表论文为测试样本,将IRRS的推荐结果与期刊原使用的Scopus推荐系统进行对比。
- 评估结果:语义匹配精度:IRRS推荐的首位审稿人与稿件的平均语义相似度(0.688)高于Scopus系统(0.596),且结果更稳定。
推荐策略差异:Scopus倾向于推荐高h-index的资深学者,而IRRS的推荐名单中包含更多学术影响力指标多样的学者,有助于发现新晋专家。
推荐理由质量:通过专家评审,IRRS生成的推荐理由在主题契合度、事实准确性、可解释性方面均获得良好评价(均值≥4.0/5.0),多样性方面尚有提升空间。
5. 结论与展望
- 结论:本研究提出的LLM与RAG融合框架,在不改变底层模型的前提下,通过外部知识库和提示词工程,有效提升了审稿人推荐的语义匹配精度和结果可解释性。系统具有模块化、易扩展、低部署门槛的特点,便于期刊编辑使用。
- 展望:未来可在更多学科领域验证其适用性,并在真实编辑流程中跟踪其实际效果(如审稿邀请接受率),以进一步优化系统,为科技期刊的数字化转型提供实用的决策支持工具。
根据提供的文章《基于大语言模型(LLM)与检索增强生成(RAG)融合机制的面向编辑辅助决策的可解释审稿人推荐方法》,其正文部分主要包含以下几个章节,现将每一章节的内容详细介绍如下:
1. 引言(未明确标出“引言”,但文章开头至“1 数据来源与研究方法”之前的内容承担此功能)
本章节阐述了研究的背景、意义、现有方法的局限以及本研究的创新点。
- 背景与问题:指出在科技期刊同行评审中,高效、精准地寻找审稿人是关键环节。自动化审稿人推荐早期主要采用基于历史评审记录的协同过滤方法,但该方法存在处理新主题、交叉学科时匹配难,以及可能导致审稿人负载不均衡的问题。
- 现有方法演进:介绍了从基于内容(如LSI、LDA、TF-IDF)到基于深度学习嵌入技术(如Word2Vec、Doc2Vec),再到利用大语言模型(LLM) 进行语义理解和推荐理由生成的技术发展路径。
- LLM应用的挑战与解决方案:指出直接应用LLM面临成本高、存在“幻觉”和知识滞后等问题。提出结合检索增强生成(RAG) 技术,通过引入外部知识库来增强LLM的可靠性和实时性,是当前有前景的方向。
- 本研究目标:提出构建融合LLM与RAG的智能审稿人推荐系统(IRRS),旨在提升语义匹配精度和推荐结果的可解释性,并为编辑决策提供支持。
2. 数据来源与研究方法
本章节详细说明了研究的数据基础、案例选择以及评估方法。
- 2.1 概念界定:明确了研究场景是“借助系统推荐”进行稿件分配,旨在验证IRRS框架的可行性与解释能力,而非进行大规模统计推断。
- 2.2 数据来源:研究样本:以《Intelligent Computing》期刊2025年已出版的20篇论文作为测试案例。
外部知识库:基于Web of Science (WoS)数据库,选取近10年计算机科学及相关交叉领域的文献元数据(作者、标题、摘要、关键词等)构建。 - 2.3 研究方法:对比系统:选择期刊系统搭载的Scopus审稿人推荐系统作为对比基准。
技术路线差异:指出Scopus基于数据库检索与统计特征分析;而IRRS采用BGE-M3嵌入模型进行语义向量化,结合向量检索与LLM生成排序。
评估方案:由于Scopus无可解释性输出,对比主要集中在语义匹配效果。对于IRRS的推荐理由质量,邀请了5名评审员(期刊编辑和领域专家)从四个维度(主题契合度、事实准确性、可解释性、多样性)进行人工评分,并引入了“自信度”指标进行加权计算。
3. 系统设计思路
本章节是文章的核心,详细阐述了IRRS系统的整体架构和各个模块的设计。
- 整体架构:IRRS分为三层:数据层:负责WoS元数据的采集、清洗(去重、作者/机构标准化、语义信息整理)与融合。
知识表征层:由两个数据库构成。关系数据库:存储结构化的实体(作者、论文、机构等)及它们之间的关联。
向量数据库:存储文献的标量字段(标题、摘要等文本)和对应的向量字段(文本的语义向量),作为RAG的外部知识库。
智能推荐层:实现核心推荐流程,包含五个组件:稿件特征向量化:将稿件标题、摘要、关键词分别编码为向量。
相似文献检索:采用“粗召回+精排序”两阶段策略,基于余弦相似度从向量库中找出与稿件最相关的Top-N篇文献。
候选审稿人信息获取:从相关文献中提取作者信息,并补充其学术指标(如h-index)。
利益冲突检测:自动检测候选人与稿件作者是否存在近期合作或机构关联。
提示词模板构建:设计双层提示词框架(系统级和用户级),引导LLM基于检索到的外部知识,生成排序后的审稿人名单及推荐理由。
4. 效果分析
本章节通过实验对比和人工评估,展示了IRRS系统的性能。
- 4.1 语义匹配效果分析:与Scopus对比,IRRS推荐的审稿人与稿件的综合语义相似度均值更高(0.688 vs. 0.596),且波动更小,表明匹配精度和稳定性更好。
在审稿人学术影响力分布上,Scopus更倾向于推荐高h-index的资深学者,而IRRS能推荐更多h-index相对较低的学者,有助于发现新晋力量。 - 4.2 生成质量效果分析:对IRRS生成的推荐理由进行人工评估,四个维度的加权平均分均较高(主题契合度4.17、事实准确性4.05、可解释性4.05、多样性3.64),表明推荐理由整体质量良好,尤其在主题匹配和事实准确性上表现突出。
提供了具体的推荐理由示例(表2),展示了系统如何从研究领域匹配度、近期活跃度、学术影响力等方面生成解释性文本。
5. 结束语
本章节总结了研究的主要贡献、实践意义,并展望了未来工作。
- 研究总结:重申IRRS框架有效提升了审稿人推荐的语义匹配精度和结果可解释性,生成的推荐理由能为编辑提供透明的决策依据。
- 实践价值:IRRS可作为独立的辅助决策工具,降低编辑筛选审稿人的时间成本。其模块化设计(可替换LLM、知识库、提示词)使得系统易于适配不同学科期刊,无需重新训练模型,降低了部署门槛。
- 未来展望:提出可从两方面深化研究:在真实编辑流程中进行长期跟踪,评估审稿人邀请接受率、审稿周期等实际效果指标。
在更多学科领域(如医学、人文社科)进行验证,提升系统的泛化能力和学科适用性。
