
 3
3 0
0这篇论文提出了一种非向量检索增强生成模型,旨在解决传统检索增强生成模型在处理多索引关联复杂查询时准确率不足的问题。
核心内容总结如下:
- 研究背景与问题:传统RAG模型依赖向量数据库进行语义相似性匹配,但在处理具有强索引关联(如时间范围、多条件筛选)的复杂查询时,性能显著下降。
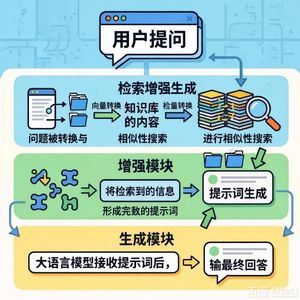
- 提出方法:作者提出了NVRAG模型。其核心创新在于:引入非向量数据库:在构建知识库时,不仅生成向量数据,还将易于提取的结构化元数据存储在独立的非向量数据库中。
集成文本到SQL技术:当检测到用户查询包含明确的结构化条件时,利用文本到SQL模型将自然语言查询转换为精确的SQL语句。
两阶段检索:先使用SQL在非向量数据库中进行精确筛选,大幅缩小相关文档的范围;然后在此范围内,再进行传统的向量相似性匹配,最后将结果交给大语言模型生成答案。 - 实验验证:在天气简报数据集上的实验表明,对于时间相关查询,NVRAG在忠实度和准确率上显著优于传统RAG模型,但其响应时间有所增加。
- 结论:NVRAG通过结合非向量精确查询和向量语义匹配,有效提升了处理复杂关联查询的能力,但以牺牲一定的响应速度为代价。该方法对知识库文档的结构化程度有一定要求。
简言之,论文通过“先用SQL精确圈定范围,再用向量搜索细化内容”的策略,增强了RAG处理复杂问题的准确性。
根据提供的文章《A Non-Vector Retrieval-Augmented Generation Model for External Time-Relevant Corpus Extraction》,以下是各章节内容的详细介绍:
1. 摘要
本章节概括了全文的核心内容。它指出,尽管大语言模型(LLM)和检索增强生成(RAG)技术在处理未训练的外部语料库方面表现出色,但在处理具有强索引关联性(如时间相关)的复杂查询时,准确性较低。为此,本文提出了一种非向量检索增强生成(NVRAG)模型。该模型基于非向量数据库和文本转SQL(Text-to-SQL) 技术,通过存储相关参数来缩小向量检索范围,从而提高索引准确性。在天气简报数据集上的实验表明,与原始RAG相比,NVRAG的忠实度(Faithfulness) 和准确率(AR) 更高,但牺牲了部分响应时间。该方法增强了系统处理复杂查询请求的能力。
2. 引言
本章节介绍了研究背景和问题。大语言模型(LLM)在许多领域已成熟应用,但在处理未预训练的数据库时,提取能力仍然不足。基于向量索引的RAG模型通过利用数据库索引来增强LLM从未训练数据中学习的能力。然而,RAG在处理具有强索引关联(如多键值查询)的问题时,准确性相对较低。这主要是因为RAG对多键值查询的优化能力不足。因此,本文提出一种基于文本转SQL(Text-to-SQL) 转换的创新方法,将用户自然语言查询转换为特定的数据库查询语句,旨在解决现有RAG模型在仅依赖向量数据库进行语义匹配时遇到的性能问题,特别是在索引和关联性挑战方面,从而提升整体查询性能和可靠性。
3. 文献综述
本章节分为两个主要部分,回顾了相关技术:
- 3.1 检索增强生成(RAG):详细介绍了传统RAG模型的两阶段工作流程(检索阶段和生成阶段)。其核心是利用向量化技术进行语义匹配,并通过Top-K方法召回相关内容。文章指出了该标准框架的一个显著缺点:其匹配算法过度依赖问答对的索引和用户语句的相似性,导致其在处理涉及多个关联索引(如时间范围统计)的查询时难以提供精确答案。
- 3.2 文本转SQL与大语言模型:介绍了基于大模型微调的Text-to-SQL方法,它能够将自然语言查询转换为结构化的SQL语句,使用户能够以自然语言与数据库交互。文章指出,LLM在自然语言理解和生成方面表现出色,而专门针对代码训练的LLM(如CodeLLaMa)能够生成符合用户需求的代码。通过微调,LLM可以针对特定数据库结构进行优化。将Text-to-SQL集成到RAG的检索模块中,可以改善信息检索能力,解决多索引联合查询的挑战。
4. 方法论
本章节详细阐述了提出的非向量检索增强生成(NVRAG)模型的工作流程,该流程通过结合非向量数据库和Text-to-SQL来增强对复杂多键值关联查询的处理能力。
- 核心思想:在RAG存储向量数据的同时,将额外的元数据(如原始问答对、索引ID、显式信息如时间、数值等)存储在独立的非向量数据库中。当检测到用户输入包含SQL相关信息(如明确的时间范围)时,利用Text-to-SQL技术将用户查询转换为精确的SQL语句,在非向量数据库中进行针对性检索,从而缩小后续向量检索的范围。
- 4.1 检索模块:在构建问答对时,通过修改提示词,引导模型识别并显式标记出易于提取的关键元素(如时间信息),并将其与非向量数据库关联。当用户输入被分类为包含SQL信息时,经过预处理的查询会被Text-to-SQL模型转换为SQL语句,用于查询非向量数据库,获取一个经过筛选的、更相关的候选问答对集合,然后再在此范围内进行传统的向量相似性匹配。
- 4.2 生成模块:负责接收用户输入,并进行预处理(文本清洗、上下文管理、指代消解)和场景分类,以过滤出可能与显式数据相关的信息。然后,它将优化后的查询传递给检索模块。最后,将检索模块返回的Top-K相关结果与用户问题结合,输入生成式AI模型以产生最终答案。
5. 实验
本章节描述了为验证NVRAG模型有效性所设计的实验。
- 评估目标:比较原始RAG模型与NVRAG模型在时间信息提取方面的能力。
- 评估指标:采用RAGAS评估框架中的忠实度(Faithfulness) 和准确率(AR)。
- 实验设置:使用FastGPT平台部署并测试两个模型。
向量检索器使用PostgreSQL的PG Vector插件(HNSW索引),非向量数据使用MongoDB。
数据集:包含100条连续数据的天气简报数据集,涵盖日期、天气状况、建议等信息,最终生成1432个键值对。
Text-to-SQL模块:使用开源模型Chat2DB_sql_7B。
生成模型:使用OpenAI GPT-3.5-turbo。测试查询:由另一个LLM生成,要求必须包含时间信息(如日期范围或多日期比较),以确保测试时间相关查询。
6. 结果
本章节展示了实验的量化结果,并通过表格(表2)进行了清晰对比。
- 主要发现:
对于一般用户查询:两种模型的忠实度和准确率相近(RAG略高),但RAG的响应时间稍快(2.10秒 vs. 2.24秒)。
对于时间相关用户查询:NVRAG模型性能显著优于原始RAG。NVRAG的忠实度(0.85)和准确率(0.91)远高于RAG(0.32和0.46)。这证明了Text-to-SQL和非向量数据库在处理复杂时间范围查询上的有效性。
权衡:NVRAG的性能提升是以更长的响应时间为代价的(3.76秒 vs. 2.98秒),因为增加了SQL查询和多步骤检索操作。但作者认为,性能的大幅提升使得这种时间开销是可接受的。
7. 结论
本章节总结了全文的工作、贡献和未来方向。
- 总结:本文提出的NVRAG模型通过引入非向量数据库和Text-to-SQL技术,有效增强了RAG模型处理多索引关联复杂查询(尤其是时间范围查询)的能力。
- 优势:NVRAG在忠实度和准确率上表现更优,解决了传统RAG在复杂查询上的局限性。
- 代价:改进带来了响应时间的增加。
- 要求与未来工作:NVRAG对知识库文档的格式有一定要求(需要易于提取的结构化信息)。未来研究应专注于优化NVRAG的响应时间,并探索其在更广泛领域和数据集上的应用,以验证其通用性和可扩展性。
8. 参考文献
本章节列出了论文中引用的相关学术文献,涵盖了大型语言模型、检索增强生成、文本转SQL、评估方法等多个相关领域的研究,为本文的工作提供了理论和技术基础。
