
 8
8 0
0这篇论文介绍了 PageIndex,一种下一代、无向量、基于推理的检索增强生成(RAG)框架,旨在克服传统向量检索RAG的局限性。
核心问题:传统向量RAG的不足
论文首先指出,尽管RAG通过检索相关文本来缓解大语言模型(LLM)的上下文窗口限制,但主流的基于向量的RAG方法存在根本缺陷:
- 查询与知识空间不匹配:查询表达意图,而向量检索只匹配语义相似的内容。
- 语义相似性不等于相关性:在专业文档中,许多段落语义相近但相关性不同。
- 硬分块破坏语义完整性:将文档固定分块会割裂上下文和逻辑。
- 无法整合聊天历史:每次查询独立处理,缺乏多轮对话的连贯性。
- 难以处理文档内部引用:无法有效跟踪如“参见附录G”这类跨章节引用。
解决方案:PageIndex的推理检索
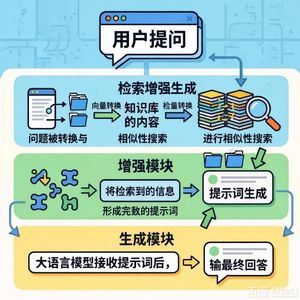
PageIndex摒弃了向量数据库和静态语义相似性匹配,提出一种基于推理的动态检索方法,其核心是让LLM像人类一样“思考”并导航文档结构。关键流程如下:
- 读取目录:理解以JSON层次化结构(“目录树”)表示的文档索引。
- 选择章节:基于问题推理,选择最可能包含答案的章节。
- 提取信息:根据
node_id定位并读取该章节的原始内容。 - 判断信息是否充足:若不足,则返回步骤1选择新章节;若充足,则生成答案。
核心创新与优势
- 无向量索引:使用结构化的“目录树”作为上下文内索引,LLM可直接对其进行推理和导航,而非依赖预计算的向量。
- 动态与连贯:检索完整的语义章节(而非固定分块),并根据需要迭代获取相邻部分,保持上下文连贯。
- 上下文感知:能够利用聊天历史来理解当前问题,实现连贯的多轮探索。
- 智能引用追踪:通过目录树结构,可以自然地跟随文档内的交叉引用找到相关信息。
总结
论文的结论是,向量RAG搜索相似文本,而推理RAG思考应该去哪里查找以及为什么。PageIndex通过结合结构化文档表示(目录树)和迭代推理,使LLM能够检索到真正相关的信息,而不仅仅是语义相似的信息,为新一代智能文档理解系统开辟了道路。
根据提供的文章,以下是关于PageIndex推理式RAG框架各章节内容的详细介绍:
1. 背景与问题引入
文章开篇指出,尽管大语言模型(LLM)能力强大,但其上下文窗口存在根本性限制,即使上下文增长,性能也会下降。为了应对此限制,检索增强生成(RAG)成为主流方案。然而,传统的基于向量的RAG方法依赖静态语义相似性,存在多个关键缺陷。为此,文章引入了PageIndex——一个基于推理的检索框架。
2. 基于向量的RAG的局限性
本章节详细阐述了传统向量RAG的五大核心问题:
- 查询与知识空间不匹配:查询往往表达意图,而非具体内容,但向量检索假设语义最相似的文本就是最相关的。
- 语义相似性不等于相关性:在专业文档(如财务、法律文件)中,许多段落语义相近但相关性截然不同。
- 硬分块破坏语义和上下文完整性:将文档机械地切分为固定长度的文本块,会割裂完整的语义单元。
- 无法整合聊天历史:每次查询都被独立处理,检索器不了解之前的对话上下文。
- 难以处理文档内部引用:对于“参见附录G”这类引用,由于与引用内容缺乏语义相似性,传统RAG无法有效追踪。
3. PageIndex:基于推理的检索
本章节是文章的核心,介绍了PageIndex的工作原理。它模仿人类阅读长文档的方式,采用动态、迭代的推理过程:
- 阅读目录(ToC):理解文档结构,识别可能相关的章节。
- 选择一个章节:基于问题,选择最可能包含有用信息的章节。
- 提取相关信息:从选定的章节中提取关键内容。
- 信息是否充分?是 → 进入第5步回答问题。
否 → 返回第1步,选择另一个章节继续循环。 - 回答问题:收集足够信息后,生成完整、有依据的答案。
文章通过一个流程图直观展示了这个迭代过程。
4. 为LLM设计的“目录”索引
本章节解释了如何为LLM构建友好的导航结构。PageIndex使用基于JSON的层次化结构来表示目录(ToC),形成一个索引树。每个节点代表一个逻辑部分(如章节、段落),包含node_id、description、metadata和sub_nodes等字段。这种“上下文内索引”使LLM能够直接引用、导航和推理,从而动态决定下一步查看哪里,而非依赖预先计算的相似度分数。
5. 如何克服传统RAG的局限性
本章节逐一对应地说明了PageIndex的推理式检索如何解决第二部分提出的五个问题:
- 解决查询-知识不匹配:通过推理推断答案可能位于哪个章节(例如,“债务趋势通常在财务摘要部分或附录G”)。
- 区分语义相似性与真正相关性:通过解读目录和查询意图,导航到实际包含答案的章节,即使其语言表述不同。
- 避免硬分块导致的语义断裂:检索语义连贯的完整部分(如整页、整节),并在需要时迭代获取相邻部分以保持逻辑连续性。
- 整合聊天历史:利用先前的对话历史来 refine 对当前问题的理解,实现跨多轮对话的连贯探索。
- 有效处理文档内部引用:利用目录或PageIndex的层次结构,像人类一样跟踪文内引用(如“参见附录G”),实现准确的交叉引用。
6. 总结:向量RAG与推理式RAG的对比
文章通过一个对比表格,总结了两种方法的本质区别:
- 向量RAG:搜索相似的文本。
- 推理式RAG:思考应该去哪里查找以及为什么。
关键区别体现在知识匹配、相关性判断、分块方式、上下文整合和跟踪引用这五个方面。推理式RAG通过结合结构化文档表示(如目录树)和迭代推理,使LLM能够检索到相关的信息,而不仅仅是相似的信息。
7. 结论与推广
文章最后得出结论,基于推理的RAG为新一代智能文档理解系统铺平了道路。同时提供了GitHub仓库链接以供查看开源代码,并说明PageIndex服务可作为ChatGPT风格的聊天平台使用,或通过MCP/API进行集成。
