
 37
37 0
0根据提供的文章,本文主要探讨了检索增强生成(RAG)在技术手册应用中的挑战与解决方案。核心内容总结如下:
1. 背景与问题:
- 工业技术手册(如制冷机、PLC系统手册)通常长达数百页、更新频繁且结构复杂,手动查找信息效率低下。
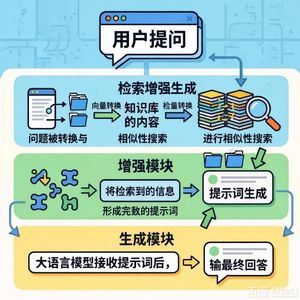
- 尽管大语言模型(LLM)支持长上下文,但性能会随文本长度增加而下降。因此,RAG成为主流解决方案,它通过检索最相关的文本片段来优化上下文。
- 然而,传统的基于向量的RAG方法在应对技术手册时存在根本性局限。
2. 传统向量RAG的四大局限(通过实例说明):
- 缺乏推理能力:仅依赖静态语义相似性匹配,无法理解步骤顺序或多跳因果关系(例如,检索到更换干燥机的步骤,却漏掉了相关的制冷剂安全警告)。
- 分块破坏语义完整性:将文档硬性分割成固定大小的文本块(分块),常会切断句子、段落或章节,导致相关上下文碎片化(例如,一个完整的检查清单被分割到两个块中,导致模型只能看到一部分)。
- 低召回率导致信息缺失:技术手册中许多术语语义相似但所指不同,向量检索可能因固定返回数量(top-K)和单次检索而错过真正相关的段落(例如,查询“高温环境导致机组进入机械模式的原因”,却检索到了关于“高温故障”的无关内容)。
- 低精确度导致上下文混淆:由于许多不同程序共享相似术语,向量检索会返回大量冗余或无关的文本块,导致模型接收到混合甚至矛盾的信息,产生错误答案或“幻觉”(例如,混淆了“开环”和“闭环”系统中乙二醇泵的作用)。
3. 提出的解决方案:PageIndex(基于推理的、无向量检索框架)
- 该框架模仿人类查阅手册的自然过程,采用动态、迭代的推理进行检索,而非依赖静态语义相似性。
- 核心流程为:阅读目录 → 选择可能相关的章节 → 提取信息 → 判断信息是否充足 → 若不足则重复此循环。
- 如何克服上述局限:具备推理能力:能根据已检索内容推断逻辑缺口(如 prerequisite、警告),并主动跳转到相关章节填补。
保持结构完整:不依赖硬分块,而是按文档的自然逻辑边界(如完整章节)进行检索,确保信息单元完整。
实现高召回率:通过迭代推理,持续评估信息是否足以回答问题,确保收集所有必要细节。
实现高精确度:基于逻辑定位到具体相关章节,避免检索语义相似但无关的“看起来像”的内容,确保上下文聚焦。
4. 总结对比:
文章通过一个对比表格和多个基于真实技术手册的问答实例,清晰地展示了向量RAG与基于推理的RAG(PageIndex) 在应对技术手册时的性能差异。结论指出,PageIndex这类方法使LLM能够像现场工程师一样逻辑性地导航技术手册,标志着从简单搜索引擎向真正智能文档理解的转变。
根据提供的文章《RAG for Technical Manuals》,其章节内容详细介绍如下:
1. 引言
- 核心问题:工业技术手册(如安装、维护指南)通常篇幅长、更新频繁且复杂。人工查阅效率低下,导致维修时间长、错误率高和设备停机成本增加。
- 现有方案与局限:虽然大语言模型支持长上下文,但研究表明随着上下文增长,模型性能会下降。检索增强生成(RAG)成为主流解决方案,它通过检索与查询最相关的文本片段来优化有效上下文长度。然而,传统的基于向量的RAG方法依赖静态语义相似性,存在关键局限。
2. 基于向量的RAG的局限性
本章详细阐述了传统向量RAG在应用于长而复杂的技术手册时面临的四个根本性挑战:
- 缺乏推理能力:仅基于静态语义相似性匹配检索文本,无法理解步骤顺序或多跳因果关系。
- 分块破坏语义完整性:将文档硬性分割为固定大小的块(如512或1000个标记),通常会切断句子、段落或章节,导致上下文碎片化。
- 低召回率导致信息缺失:技术手册中许多段落语义相似但相关性不同,在固定top-K检索和单次检索下,真正相关的部分常常无法被检索到。
- 低精确度导致上下文混淆:由于检索到许多语义相似的段落,大语言模型会收到冗余甚至不一致的文本块,导致答案嘈杂且有时不正确。
3. PageIndex:基于无向量推理的检索
本章介绍了PageIndex框架,这是一种模仿人类自然浏览长文档方式的推理检索方法。
- 核心原理:不同于依赖静态语义相似性的传统方法,它采用动态、迭代的推理过程,基于问题的演进上下文主动决定下一步查找位置。
- 工作流程:阅读目录,理解文档结构并识别可能相关的章节。
根据问题选择最可能包含有用信息的章节。
解析所选章节以收集有助于回答问题的内容。
判断信息是否充分。如果否,则返回步骤1,循环选择另一章节;如果是,则回答问题。
4. 克服技术手册中基于向量的RAG局限性
本章通过并排的问答示例,具体分析了上述四个局限性,并展示PageIndex的推理框架如何克服它们。对比双方是:基于向量的RAG(以Google的Gemini File Search RAG API为例)和基于推理的RAG(以PageIndex Chat为例)。
- 针对“缺乏推理能力”:向量RAG失败案例:对于“如何更换干燥器及适用哪些安全预防措施?”的问题,它只检索到第29页的机械步骤,但遗漏了第6页关键的“制冷剂警告”。
PageIndex成功案例:通过结构感知推理,在找到干燥器程序后,根据步骤中提到的“制冷剂泄漏”推断需要安全指导,进而检索到第6页的警告。 - 针对“分块破坏语义完整性”:向量RAG失败案例:对于关于“安装前检查清单”和“吊耳位置图示”的问题,由于固定分块,检索的文本块在清单开始处截断,导致模型看不到后续的实际列表项;同时因语义权重偏差,遗漏了部分图示(图5-7)。
PageIndex成功案例:通过无分块策略和结构感知,在文档结构层面操作,保持了清单内容和相关说明的完整性;并通过推理引用关系,捕获了全部相关图示(图5-12)。 - 针对“低召回率导致信息缺失”:向量RAG失败案例:对于“为何高环境温度会导致机组进入机械模式?”的问题,它检索到描述“高环境温度故障”的文本,但未检索到第142页解释控制逻辑机制的关键部分。
PageIndex成功案例:通过迭代推理和结构感知,首先定位到“运行模式”章节,然后综合多步控制逻辑,正确解释了触发机制,并检查了相关页面以验证上下文。 - 针对“低精确度导致上下文混淆”:向量RAG失败案例:对于“闭式自由冷却何时需要乙二醇泵?”的问题,它同时检索到开环和闭环系统的段落,由于术语相似,模型混淆了细节,给出了包含阀门(属于开环)和虚构的泵充电功能等错误答案。
PageIndex成功案例:通过逻辑导航,直接定位到描述闭环配置的特定章节,排除了混淆的开环内容,给出了准确答案。
5. 总结:向量检索与推理检索的RAG对比
本章通过一个对比表格总结了两种方法的差异:
- 缺乏推理:向量RAG仅执行静态相似性搜索;推理RAG将检索视为动态推理过程。
- 分块破坏完整性:向量RAG的硬分块导致上下文割裂;推理RAG避免人工分块,保留完整文档结构。
- 低召回率:向量RAG常因术语差异遗漏相关信息;推理RAG通过迭代推理确保高召回率。
- 低精确度:向量RAG检索冗余相似块导致上下文混淆和幻觉;推理RAG基于逻辑导航到特定相关章节,避免噪声。
6. 结论
- 文章总结,对于技术手册等复杂长文档,基于向量的RAG存在结构上的根本限制。PageIndex提出的基于推理的检索框架通过模仿人类专家的逻辑导航和迭代查找,有效克服了这些限制。
- 它使大语言模型能够像现场工程师一样逻辑清晰地浏览技术手册,标志着从简单搜索引擎向真正智能文档理解系统的转变,可提供可靠、上下文感知且符合实际工作流程的答案。
