


 145
145 2
2前游戏开发者,现海外云厂商架构师 [反向弯曲] 主理的 [AI×游戏] 播客!
帮助互联网|游戏从业人员 拆解全球游戏 AI 前沿动态,深挖技术落地干货。
让你轻松拿捏行业脉搏,预判 AI + 游戏的 "下一帧"。
对未来好奇?速戳订阅!
小红书b站同名:反向弯曲
=====================================
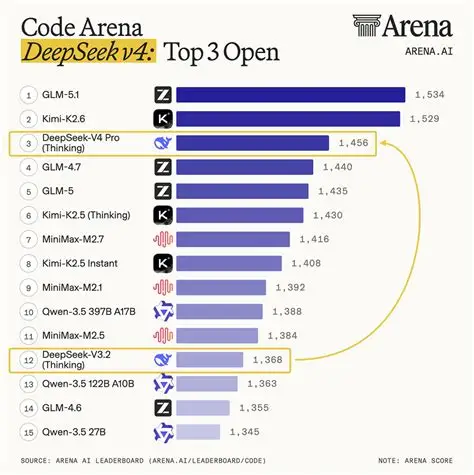
1.6万亿参数,只激活490亿。100万token上下文,算力只要上一代的27%,显存只要10%。MIT开源,价格是GPT-5.5的几十分之一。
DeepSeek V4来了。
这不是简单的版本迭代——这是一个160人的中国团队,在芯片受限的条件下,重新发明了注意力机制。
本期我们从幻方量化到深度求索的创业故事讲起,完整回顾V2→V3→R1→V3.2→V4的技术演进脉络。然后掀开V4的引擎盖:CSA+HCA双轨注意力如何让百万上下文成为可能?从NanoGPT speedrun社区诞生的Muon优化器怎么被用到万亿参数训练?"先分后合"的后训练新范式有多巧妙?
当然也有硬核横评——编程第一、Agent短板、知识类差距,优势和不足都摆出来。加上一个月900美元vs8.4美元的价格炸弹,以及华为芯片适配背后的技术栈独立性。
不管你是技术人还是产品经理,这期都值得听完。
=====================================
开场:幻方量化到DeepSeek的创业故事
DeepSeek V2
DeepSeek V3
DeepSeek R1
DeepSeek V3.2
DeepSeek V4
推理优化1:CSA压缩+稀疏三步走
推理优化2:HCA极端压缩 + 为什么两种注意力混着用
训练优化1:Muon优化器:从业余speedrun社区到万亿模型
训练优化2:mHC:给信息高速公路装交通灯
训练优化3:FP4+FP8混合精度
Post-Training新范式:先分再合
竞争格局横评:编程/Agent/数学/知识/长上下文
收尾:「不诱于誉,不恐于诽,率道而行,端然正己」
=====================================

