25372
25372 62
622026 年 3 月,英伟达年度开发者大会 GTC 在美国 San Jose 开幕。这一年的 GTC 气氛与往年明显不同——黄仁勋不再需要向市场证明 AI 的价值,因为 Agent 爆发和开源模型崛起已经让算力需求成为行业共识,Token 消耗量正在以百倍速度增长。
本期节目,Diane 在 GTC 现场为大家带来了第一手的观察,也专访了推理优化初创公司 Eigen AI 的联合创始人。Eigen AI 由三位 MIT 背景的创始人于 2024 年中创立,主攻开源大模型的推理加速与企业定制化部署。这次 GTC,他们的推理速度跑分直接登上了黄仁勋 Keynote 的大屏幕,是当前推理速度最快的团队之一。
节目里我们深入聊了为什么推理层正在成为 AI 行业最重要的竞争战场、GPU 和 LPU 各自在推理过程中扮演什么角色、英伟达斥资约 200 亿美元收购 Groq 背后的战略逻辑,以及当前 AI 应用的商业模式为何正在面临系统性挑战。
本期人物
丁教 Diane,「声动活泼」联合创始人、「科技早知道」主播
Di Jin,Co-founder at Eigen AI
主要话题
00:11 今年 GTC 最大的不同是什么?
- 黄仁勋状态明显更放松,不再需要向市场"推销" AI 的价值
- Agent 爆发让 Token 消耗量指数级增长,算力需求已成行业共识
- 开源模型崛起打开了推理层的商业空间,这一层开始变得关键
09:13 Eigen 是一家什么样的公司,在做什么?
- 三位 MIT 背景创始人,专攻模型压缩与推理加速
- Post Training 帮企业定制模型,Inference 加速让模型跑得更快更便宜
- GTC 开幕前两天完成技术突破,推理速度登上黄仁勋 Keynote 大屏幕
13:24 过去一年 AI 行业最大的结构性变化是什么?
- 模型训练层高度集中,GPU 成本比人才成本贵 10 到 100 倍,中小公司已基本出局
- Reasoning(推理时扩展)成为新的性能提升路径,让固定模型通过多花算力输出更好结果
- Agent 工作流让 Token 消耗量远超对话场景,推理层的优化价值随之暴增
23:34 英伟达为什么要花约 200 亿美元收购 Groq?GPU 和 LPU 各自擅长什么?
- AI 生成回答分两阶段:读懂问题(Prefill)适合 GPU 并行处理,逐字生成答案(Decoding)适合 LPU 串行提速
- 当前最快模型约每秒 1000 个 Token,Agent 场景未来可能需要每秒 10000 个,GPU 单独难以跨越这道坎
- GPU 负责前段、LPU 接手后段,两者组合是目前长序列推理的最优解
34:04 推理优化的技术路径有哪些,分几个层次?
- 底层是 CUDA 算子优化,针对不同模型的矩阵计算特点做精细调整
- 中间层包括量化(降低数字精度)、剪枝(删除冗余专家模块)、投机解码(小模型预测 + 大模型验证)
- 最上层是调度与路由,核心是把请求打到存有对应 KV Cache 的 GPU 上,避免重复计算
44:05 推理优化怎么在速度、精度和成本之间做取舍?
- 完全不掉精度、少量掉精度、需要后训练恢复精度,三类方案对应不同客户需求
- 对话场景最看重 TTFT(第一个字的响应时间),Agent 场景更看重整体任务完成时间
- 语音交互场景存在天花板:模型再快也超不过人能听懂的速度,快到一定程度就没有意义了
47:28 AI 应用的商业模式为什么正在出现系统性问题?
- SaaS 订阅制是历史遗留:以前软件边际成本接近零,现在每用一次 AI 都在真实烧钱
- 重度用户轻松"用穿"月度套餐,公司不得不限流,引发用户强烈反弹
- 更合理的方向是按任务完成量收费,但用户心理锚点还没有完成迁移,行业仍在震荡期
53:52 开源模型能追上闭源模型吗?推理层未来最大的机会在哪?
- 行业最大的非共识:开源模型到底能不能真正追上闭源,以及 AGI 算不算已经到来
- 推理层几乎只能服务开源模型,开源能力的拐点直接决定这个赛道的天花板
- 一旦开源模型达到拐点,Token 将像电力一样渗透各行各业,推理层的市场规模将彻底打开
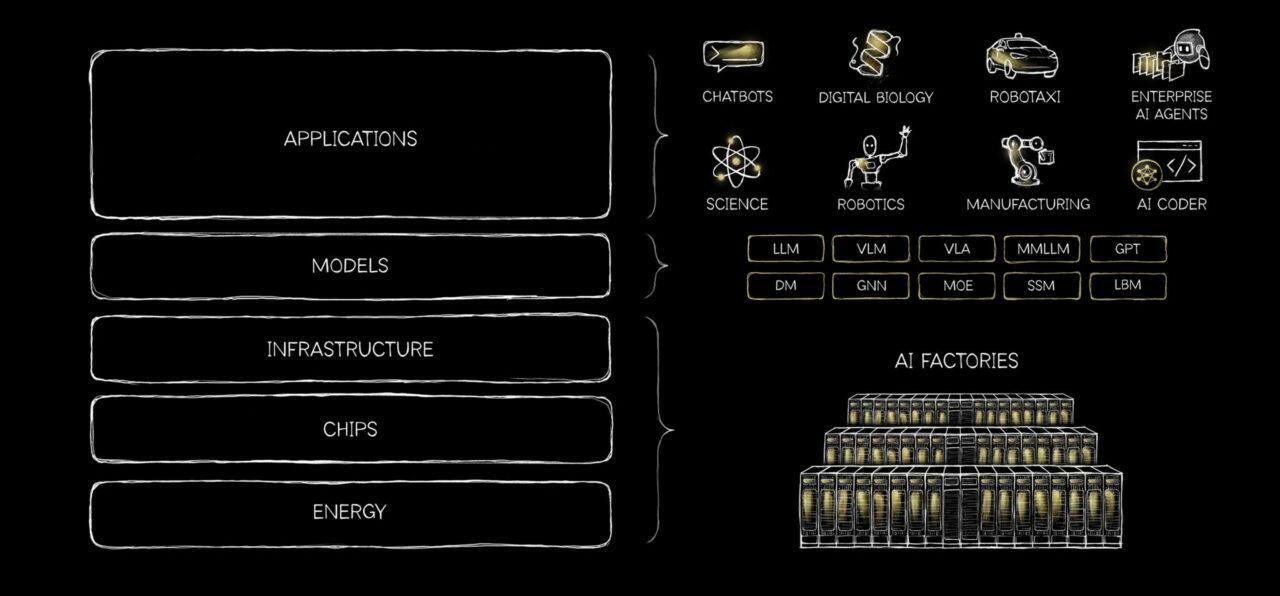
黄仁勋的「AI 五层蛋糕」模型
名词解释
LPU(Language Processing Unit)
Groq 公司研发的专用芯片,专为大语言模型的文字生成(Decoding)环节优化,通过把高带宽内存直接集成在芯片上,大幅提升了逐字生成的速度,但牺牲了通用性。
TPU(Tensor Processing Unit)
谷歌专为自身 AI 需求定制的芯片,性能强劲且价格相对便宜,但目前仅面向 OpenAI、Anthropic 等少数大型客户供货,缺乏开放的开发者生态。
Quantization(量化)
降低模型内部数字精度以节省存储和计算量的技术。好比把精确到小数点后 10 位的数字改写成精确到 2 位——计算量大幅下降,但对最终输出影响有限。精度从高到低依次为 FP32、BF16、INT8、INT4,越低效率越高,但掉点风险也越大。
Pruning(剪枝)
识别并删除模型中冗余参数或模块的技术。以 MoE 架构为例,模型内部有大量从未被有效训练的"伪专家",将其删除后模型精度几乎不受影响,但推理速度和效率显著提升。
Speculative Decoding(投机解码)
先用小模型快速"草拟"若干 Token,再让大模型批量验证并决定是否采纳的加速技术。当草稿被采纳的概率足够高时,整体推理速度可提升 50% 以上。
KV Cache(键值缓存)
AI 在生成回答过程中,将对前文的"理解结果"缓存起来,避免每次都重新读取和计算全部历史内容。合理调度 KV Cache 是 Agent 场景下降低延迟和成本的关键技术之一。
MoE(Mixture of Experts,专家混合架构)
模型内部由多个"专家"子模块组成,每次推理只激活其中最匹配当前任务的少数几个。DeepSeek、Qwen 等主流开源模型均采用此架构,可在维持大参数量的同时显著降低实际计算开销。
SLA(Service Level Agreement,服务水平协议)
对服务质量的量化约定,例如"首字响应时间不超过 300 毫秒"或"每秒至少输出多少个 Token"。推理层的大多数技术决策,都是围绕在成本约束下满足客户 SLA 要求来展开的。
TTFT(Time to First Token,首字时延)
从用户发出请求到收到第一个输出字符的时间间隔。对话类产品中这一指标最为关键,直接影响用户对系统响应速度的主观感受。
「Knock Knock 世界」
上周「Knock Knock 世界」更新了「数字收藏」话题:一段视频、一个表情为什么也能成为博物馆的收藏品?点击这里收听节目👉sourl.co
「Knock Knock 世界」是一档适合9岁以上青少年收听的播客,你可以听到全球新鲜事,还能成为「全球观察员」,报选题、参加选题会。2026 年的节目正在持续更新中,可以在各大音频平台搜索订阅。
幕后制作
监制:Yaxian
后期:迪卡
运营:George
设计:饭团
商业合作
声动活泼商业化小队,点击链接直达声动商务会客厅(sourl.cn ),也可发送邮件至 business@shengfm.cn 联系我们。
加入声动活泼
声动活泼目前开放商务合作实习生、社群运营实习生和 BD 经理等职位,详情点击招聘入口详情点击招聘入口
关于声动活泼
「用声音碰撞世界」,声动活泼致力于为人们提供源源不断的思考养料。
我们还有这些播客:声动早咖啡、声东击西、吃喝玩乐了不起、反潮流俱乐部、泡腾 VC、商业WHY酱、跳进兔子洞 、不止金钱
欢迎在即刻、微博等社交媒体上与我们互动,搜索 声动活泼 即可找到我们。
期待你给我们写邮件,邮箱地址是:ting@sheng.fm
欢迎扫码添加声小音,在节目之外和我们保持联系。
Special Guest: Di Jin.